Xception
-
GoogLeNet의 Inception 구조에 대한 고찰로 연구를 시작하였으며, 추후 많은 연구들에서 사용이 되는 연산인 “depthwise-separable convolution”을 제안하고 있다. Inception-v1, 즉, GoogLeNet에서는 여러 갈래로 연산을 쪼갠 뒤 합치는 방식을 이용함으로써 cross channel correlation과 spatial correlation을 적절히 분리할 수 있다고 주장하고 있다. 쉽게 설명하자면, 채널간의 상관관계와 image의 지역적인 상관관계를 분리해서 학습하도록 가이드를 주는 Inception module을 제안한 것이다.
-
기존의 convolution layer는 2개의 spatial dimension(width, height)과 channel dimension으로 이루어진 3D 공간에 대한 filter를 학습하려고 시도한 것이다. 따라서 single convolution kernel은 cross-channel correlation과 spatial correlation을 동시에 mapping하는 작업을 수행한다고 할 수 있다.
-
GoogLeNet의 Inception module의 기본 아이디어는 이러한 cross-channel correlation과 spatial correlation을 독립적으로 볼 수 있도록 일련의 작업을 명시적으로 분리함으로써, 이 프로세스를 보다 쉽고 효율적으로 만드는 것이다.
-
일반적인 Inception module의 경우, 우선 1x1 convolution으로 cross-correlation을 보고, input보다 작은 3~4개의 spatial 공간에 mapping한다. 그다음 보다 작아진 3D 공간에 3x3 혹은 5x5 convolution을 수행하여 spatial correlation을 mapping한다.
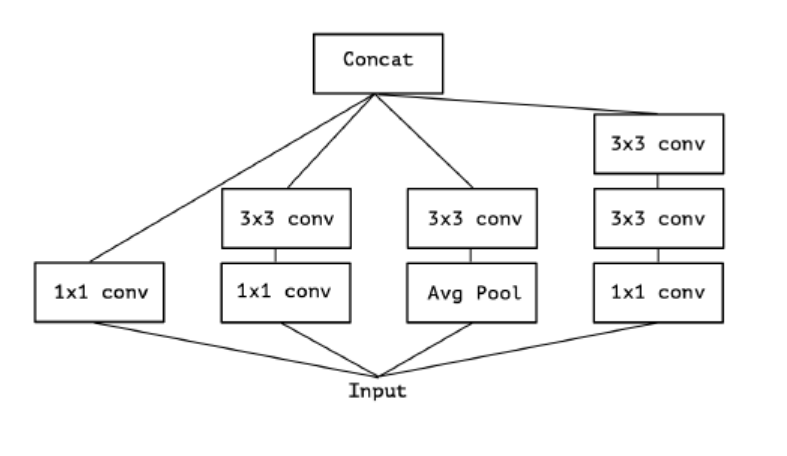
- Inception module은 기존의 위와 같은 구조를 단순화시키고, cross-channel correlation과 spatial correlatino이 함께 mapping이 되지 않도록 분리하는 형태로 구조를 변화시켰다.
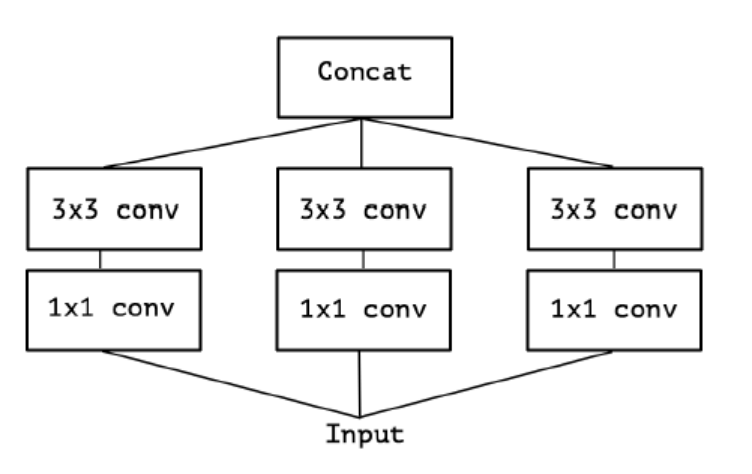
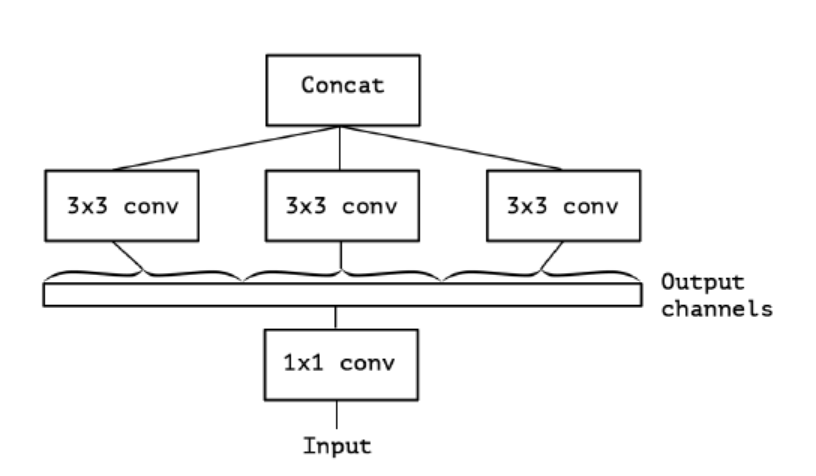
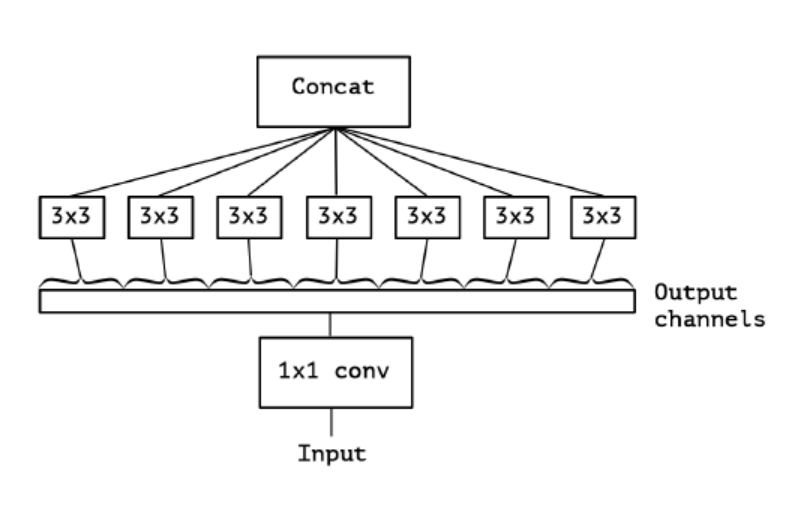
- 위의 마지막 그림은 extreme version의 Inception moduel로, 먼저 1x1 convolution으로 cross-channel correlation을 mapping하고, 모든 output channel들의 spatial correlation들의 spatial correlation을 따로 mapping한다.
-
-
Xception은 Inception module이 지향하고자 한, 채널간의 상관관계와 image의 지역적인 상관관계를 완벽하게 분리하는 더 높은 목표를 세우고 연구를 시작하였고, 그것이 바로 depthwise separable convolution이다. 위의 그림에 나오는 extreme version의 module은 depthwise separable convolution과 거의 동일하다고 할 수 있지만, 2가지의 차이점이 있다.
1) Operation의 순서
: Inception에서는 1x1 convolution을 먼저 수행하는 반면, Tensorflow와 같이 일반적으로 구현된 depthwise separable convolution은 channel-wise spatial convolution을 먼저 수행한 뒤(depthwise convolution)에 1x1 convolution을 수행(pointwise convolution)한다.2) 첫 번째 operation 뒤의 non-linearity 여부
: Inception에서는 두 operation 모두 non-linearity로 ReLU가 뒤따르는 반면, separable convolution은 일반적으로 non-linearity 없이 구현된다. 실험을 통해 연산의 지역 정보와 채널간의 상관관계를 연산하는 사이에 non-linearity 함수가 있으면 성능이 크게 저하된다는 사실을 알게되었기 때문이다.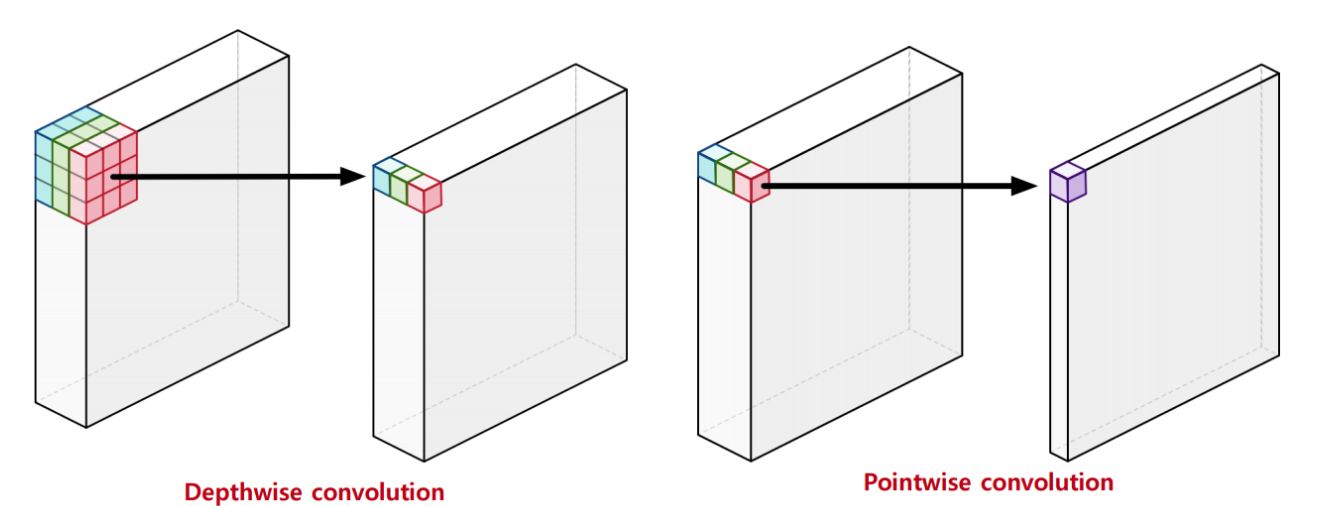
구조
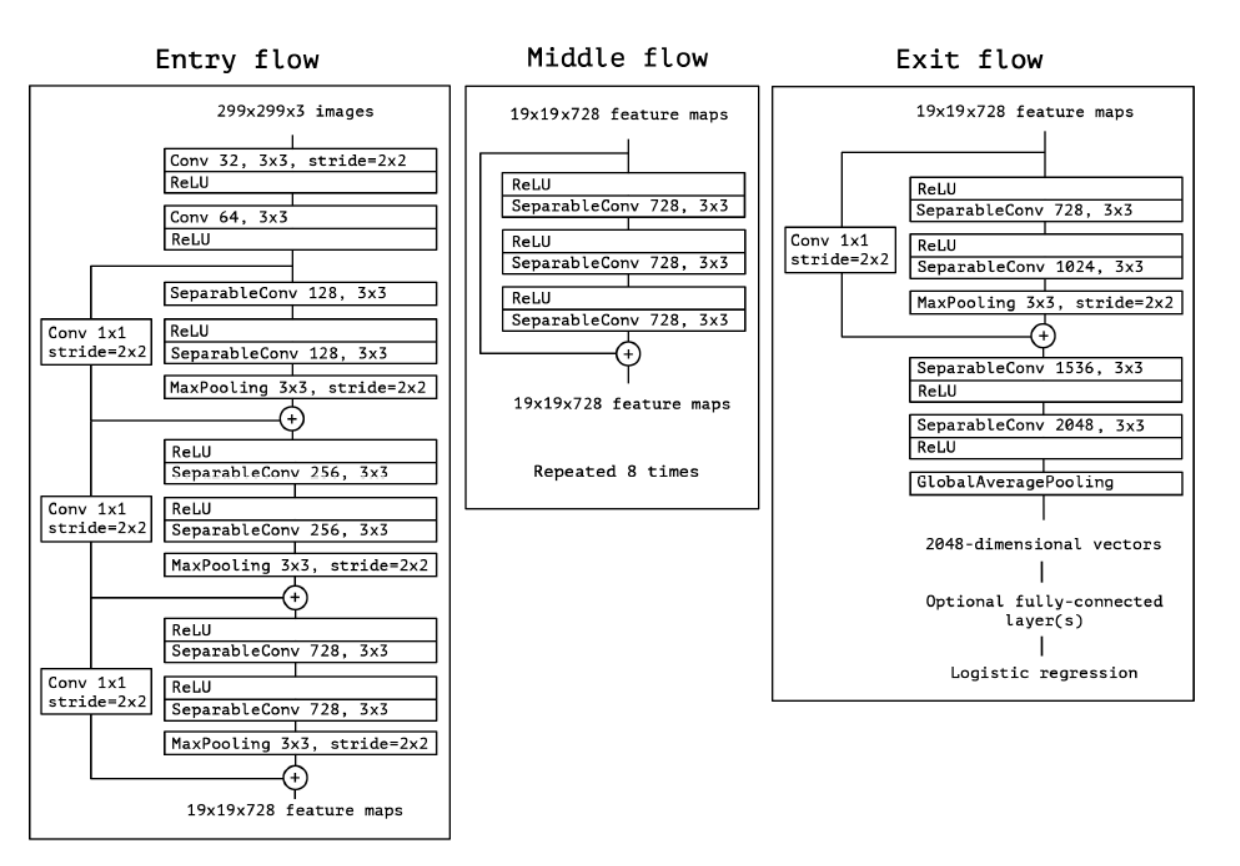
-
Xception 구조는 36개의 convolution layer로 feature extraction을 수행한다. Entry flow를 시작으로, 8회 반복되는 middle flow, 마지막에는 exit flow를 거치는 구조이다.
- 모든 convolution과 separable convolution의 뒤에는 BN(Batch Normalization)이 뒤따른다.
- BN(Batch Normalization)이란? Deep Learning Concept를 참고
- 요약하자면, Xception 구조는 residual connection이 있는 depthwise separable convolution의 linear stack으로 볼 수 있다.
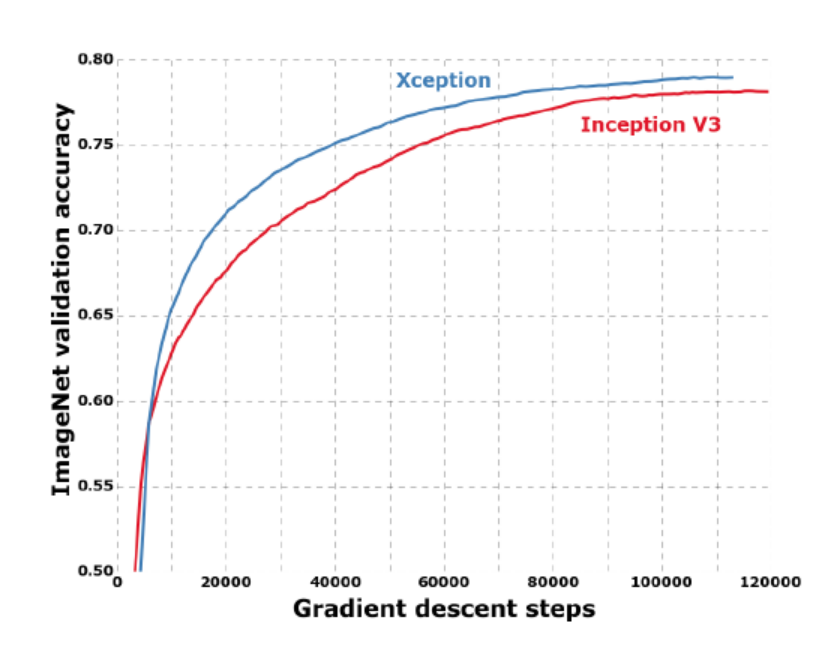
참고자료
(Xception) Xception: Deep Learning with Depthwise Separable Convolutions 번역 및 추가 설명과 Keras 구현