딥러닝 기반 객체 인식 기술 동향(ETRI)
1. 과거의 객체 인식 연구
1.1. 과거의 객체 인식 연구는 SHIFT(Scale Invariant Feature Transform), SURF(Speeded-Up Robust Features), Haar, 4) HOG(Histogram of Oriented Gradients) 등과 같이 객체가 가지는 특징을 설계하고 검출함으로써 객체를 찾아내는 방식으로 진행.
1.2. 예를 들면 책의 경우, 영상에서는 사다리꼴 형태로 나타나고 꼭짓점에서는 각이 생기는 특징 -> DPM(Deformable Part-based Model)을 이용해 물체를 여러 부분으로 나누어 특징 정보 구성 -> SVM(Support Vector Machine)을 이용해 기계학습
1.3. 합성곱 신경망(CNN) 등장 이후부터 딥러닝을 이용한 객체 인식 방법이 주류가 됨. 따라서 자연스럽게 CNN의 인식률 향상을 위해 ZFNet, VGG, ResNet, GoogLeNet, DenseNet 등이 등장.
1.4. CNN을 통해 영상에서 객체가 무엇(what)인지 인식은 성공하였으나, 객체가 어디(where)에 존재하는 지 고민
- R-CNN(Region-based CNN)은 where를 찾기 위해 딥러닝 회귀 방법으로 해결한 초기 연구
- Fast R-CNN은 R-CNN의 느린 속도를 보완하였지만, 객체의 후보 영역을 찾기 위해 딥러닝을 이용할 수 없었음.
- Faster R-CNN은 검출 속도를 향상시키고, 딥러닝만을 이용해 객체 인식 구현 가능
- R-FCN은 Faster R-CNN의 영상의 지역적 정보에 의존적이라는 점을 보완
- YOLO(You Only Look Once)는 실시간에 가까운 처리 속도 문제와 객체 인식의 모든 과정을 하나의 딥러닝 네트워크로 구성하는 방법을 제안
2. 객체 인식 기술 동향
2.1. 객체 인식 방법
- R-CNN(Region-based CNN)
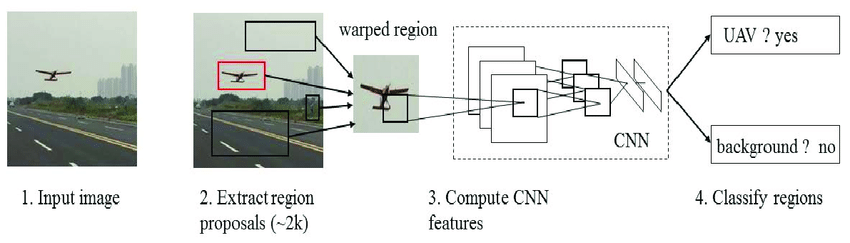
- 후보 영역(Region Proposal)을 생성하고 이를 기반으로 CNN을 학습시켜 영상 내 객체의 위치를 찾아내는 방법이다.
- 객체 인식 과정은 크게 네 단계로 이루어진다.
1) 입력된 영상에서 선택적 탐색(Selective Search) 알고리즘을 이용하여 후보 영역들을 생성한다.
2) 생성된 각 후보 영역들을 동일한 크기로 변환하고, CNN을 통해 특징을 추출한다.
3) 추출된 특징을 이용하여 후보 영역 내의 객체를 SVM(Support Vector Machine)을 이용하여 분류한다.
4) 첫 번째 단계에서 생성된 후보 영역의 위치는 정확하지 않기 때문에, 최종적으로 회귀학습을 통해 객체의 영역 박스 위치를 더 정확히 보정한다.
- Fast R-CNN
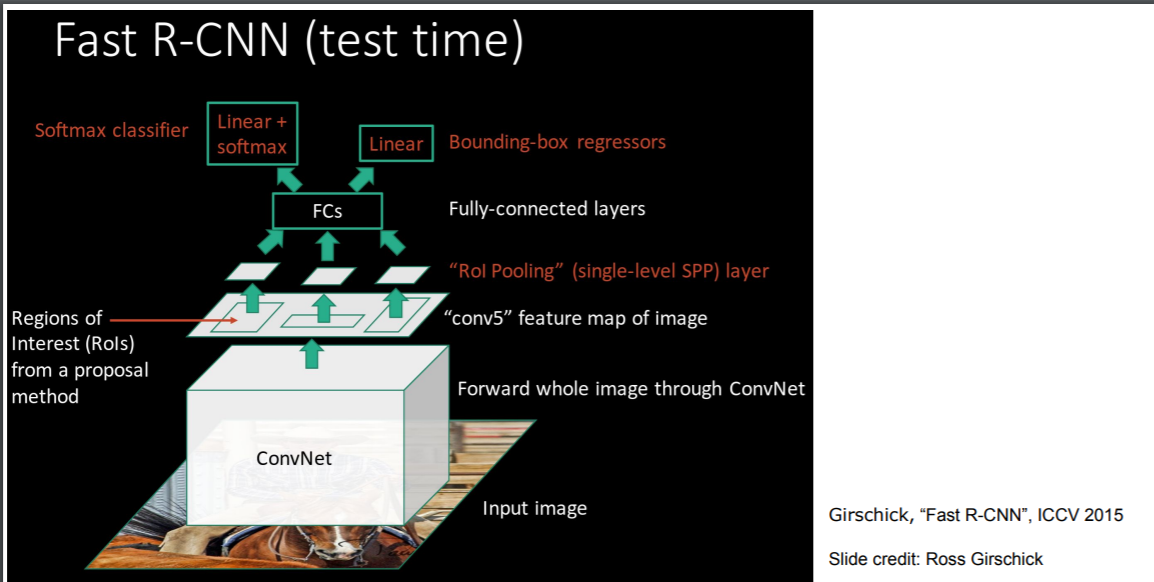
- R-CNN은 CNN, SVM, 회귀의 학습 단계가 모두 분리되어 있고, 수천 개의 후보 영역에서 각각의 CNN을 학습해야 하므로 훈련 시간이 많이 소요된다. 이를 보완하기 위해, 하나의 입력 영상에 대해 하나의 CNN을 학습할 수 있는 Fast R-CNN이 등장하였다.
- 학습된 CNN을 통해 생성된 Feature map을 통합하여 특징을 추출한다. 또한, 분류기의 손실과 영역 박스 회귀의 손실을 합하여 동시에 훈련시킴으로써 훈련 단계를 단순화하였다. 분류기로는 Softmax를 사용한다.
- Faster R-CNN
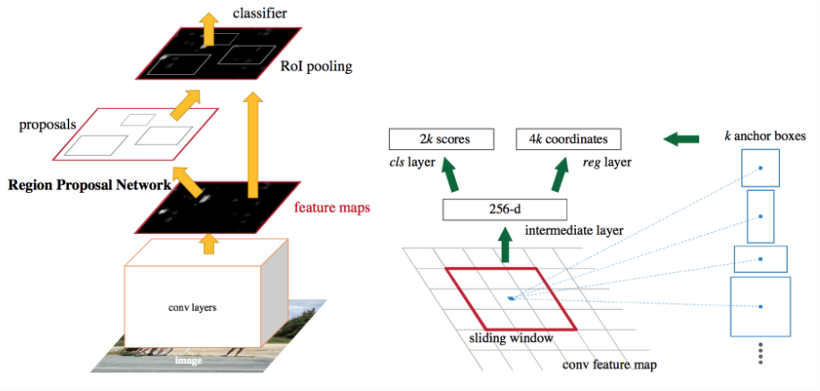
- Fast R-CNN에서 후보 영역을 생성하는 선택적 탐색 알고리즘은 CNN 외부에서 수행되기 때문에, 속도 측면에서 비효율적이며, 알고리즘을 학습시킬 수 없다는 단점이 있다.
- Faster R-CNN은 선택적 탐색 알고리즘을 사용하지 않고, Feature map을 추출하는 CNN의 마지막 층(Layer)에 후보 영역을 생성하는 별도의 CNN인 영역 제안 네트워크(RPN: Region Proposal Network)를 적용한다.
- RPN은 R-CNN에서 CNN의 출력인 Feature map을 입력으로 받아 객체의 위치를 추정하여 후보 영역을 출력하는 네트워크이다. CNN에서 추출된 Feature map을 RPN에서 추정된 후보 영역으로 잘라내어 객체를 인식한다. 이렇게 Feature map을 추출하는 CNN 과정과 후보 영역을 생성하는 과정을 일련의 네트워크로 구성함으로써 속도 개선을 시켰다.
- R-FCN
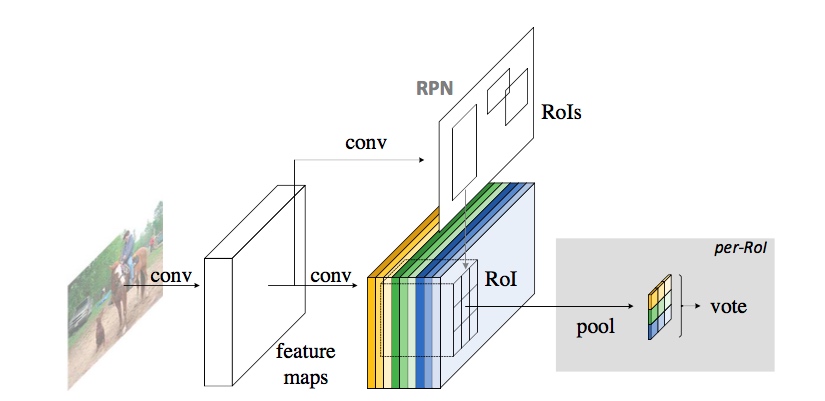
- R-FCN은 위치 정보를 포함하고 있는 Score map을 이용하여 물체의 위치를 정확하고 효율적으로 찾아냄. 이 Score map은 CNN을 통해 추출된 Feature map으로부터 얻어지며, 각 Score map은 입력된 영상 내 특정 위치의 정보를 포함함. 이를 이용하여 특정 위치마다 분류 결과를 얻어내고, 이 결과를 종합하여 최종적으로 특정 위치 내의 객체를 분류.
- 특정 위치가 찾고자 하는 객체를 포함할 경우, Score map의 반응이 커짐.
- 특정 위치가 찾고자 하는 객체를 포함하지 않을 경우, Score map의 반응이 작아짐.
- Score map은 위치 정보를 포함하고 있기 때문에, 후보 영역을 추출하기 위한 별도의 학습 시간이 필요 없음.
- YOLO
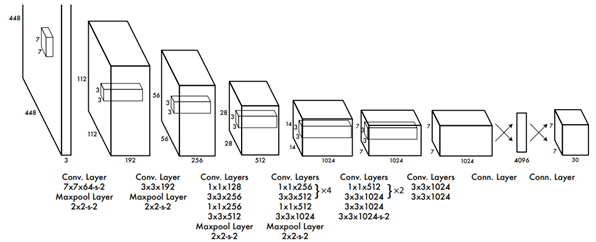
- YOLO는 객체 인식 문제를 하나의 회귀 문제로 접근하여 전체적인 구조를 간소화함으로써 훈련 및 검출 속도를 크게 향상시킴.
- 입력된 영상은 CNN을 거쳐 텐서(Tensor) 형태로 출력됨. 이 텐서는 영상을 격자 형태로 나누어 각 구역을 표현하게 되며, 이를 통해 해당 구역의 객체를 인식함.
- YOLO는 후보 영역을 추출하기 위한 별도의 네트워크가 필요하지 않으며, 일련의 추론 과정을 통해 객체를 인식함.
- Faster R-CNN보다 훈련 속도는 빠르지만, 인식 정확도는 다소 떨어짐.
- SSD
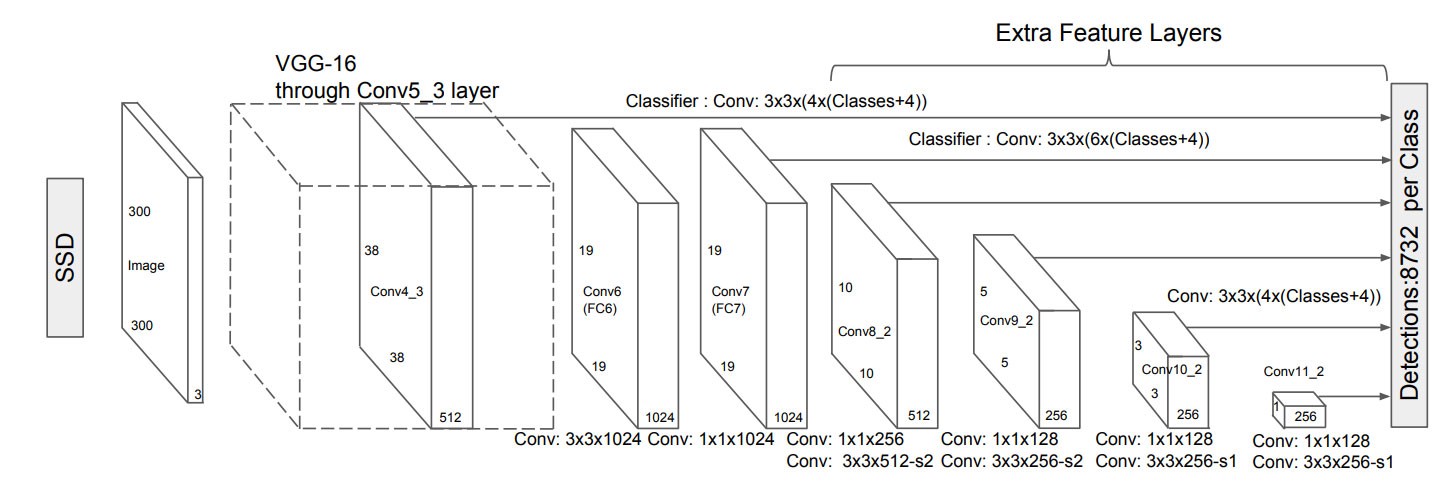
- SSD는 후보 영역을 생성하기 위한 RPN을 따로 훈련시키지 않고, 다양한 크기의 Feature map을 이용하여 객체를 인식함.
- CNN 모델로부터 얻은 Feature map은 합성곱 층이 진행됨에 따라 크기가 줄어들며, 이 과정에서 추출된 모든 Feature map들을 추론 과정에 사용하여 객체를 인식함.
- 얕은 깊이에서 추출되어 크기가 큰 Feature map은 작은 물체들을 검출할 수 있고, 깊은 깊이에서 추출되어 크기가 작은 Feature map은 큰 물체들을 검출할 수 있음.
- SSD는 RPN을 제거함으로써 훈련 속도를 향상시켰으며, 다양한 크기의 Feature map을 이용하여 객체를 인식하기 때문에 YOLO보다 정확함.
2.2. 객체 인식 모델
- AlexNet
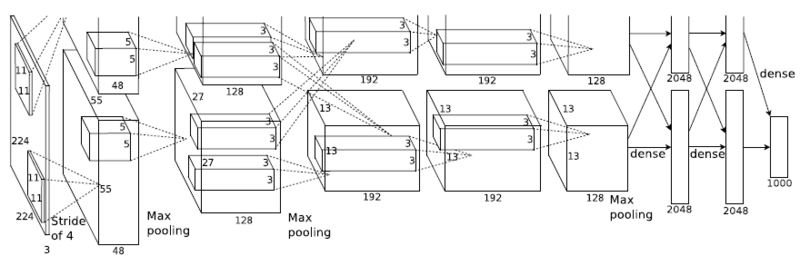
- 8개의 층으로 이루어진 CNN 구조로, 이전보다 규모가 크고 깊은 CNN을 사용함. 이로 인해 발생되는 과적합 문제를 방지하기 위해, 2개의 GPU를 사용함.
- AlexNet은 5개의 합성곱 층과 3개의 완전하게 연결된 층(Fully-Connected Layer)으로 이루어진 2개의 CNN이 병렬적으로 구성되어 있고, 2개의 GPU를 이용하여 각 CNN을 학습함.
- 활성 함수로는 ReLU(Rectified Linear Unit)을 사용하여 학습 속도를 약 6배 향상시킴.
- 과적합을 방지하기 위해 입력 영상을 임의로 잘라내거나 픽셀의 밝기를 조정하는 데이터 가공 방법을 이용하고, 완전연결 층에 Dropout을 적용.
- ZFNet
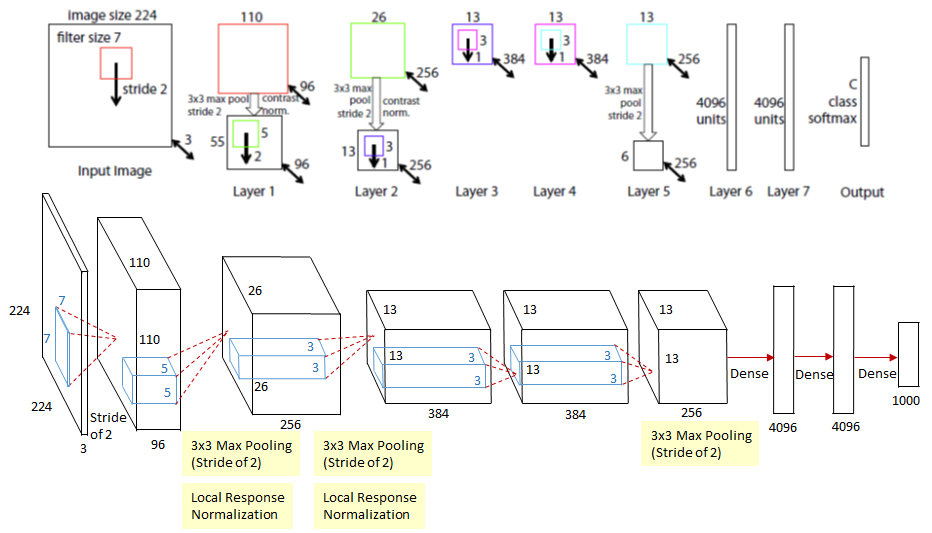
- AlexNet을 개선한 모델로, CNN 모델 내부의 층들을 시각화하는 방법
- CNN 내부의 한 층을 시각화하기 위해, 층의 반응을 입력 영상의 크기로 매핑하여야 함. 하나의 층은 합성곱, 활성, 통합의 세 가지 과정으로 이루어져 있기 때문에, 이를 각 층마다 역으로 수행하여, 입력 영상의 크기로 매핑함.
- 5개의 합성곱 층 중 얕은 층에서는 선이나 모양 등의 단순한 특징들이 추출되고, 깊은 층에서는 객체의 형태와 가까운 특징들이 추출됨.
- 합성곱 층을 시각화여 얻어낸 정보를 이용하여 AlexNet의 초기 층을 수정하였고, AlexNet보다 높은 분류 정확도를 보임.
- VGG
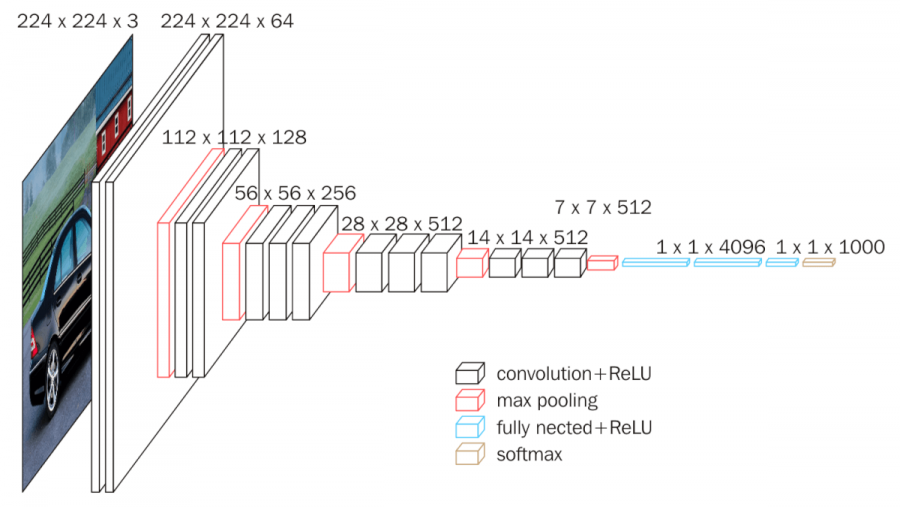
- VGG는 CNN의 층 깊이에 따른 성능의 변화를 연구를 통해 제안되었으며, 모델의 구조에서 층의 깊이를 제외한 모든 조건을 공평하게 하기 위해 각 모델의 설정을 동일(5번의 통합, 모든 필터의 크기를 3으로 설정)하게 사용함.
- VGG 모델은 필터의 크기를 3으로 설정하고 반복적으로 사용하면 더 큰 크기의 필터의 역할을 할 수 있다는 점을 강조하였고, 이후에 개발된 많은 모델에서 필터의 크기를 3으로 사용함.
- GoogLeNet
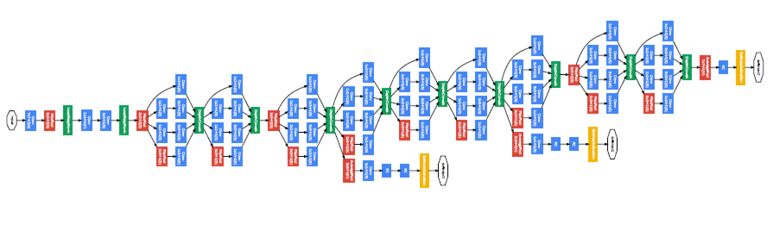
- CNN의 성능을 향상시키기 위해서는 구조를 깊게 하는 방법이 있지만, 이는 과적합이나 기울기 값의 소실 문제가 일어날 가능성이 높고, 요구되는 연산량이 급격하게 증가함. 이러한 문제는 CNN의 밀도를 낮게(Sparse)하여 해결할 수 있지만, 연산량 측면에서는 밀도가 높은(Dense) 구조가 효과적임.
- GoogLeNet은 위의 2가지 장점을 적절히 포함하는 Inception 모듈을 개발하여 적용.
- Inception 모듈은 여러 크기의 합성곱 층과 통합 층이 병행하게 수행되고 그 결과를 합침으로써 다양한 특징을 추출할 수 있음.
- 여러 크기의 합성곱을 수행하기 때문에 연산량이 많이 요구되지만, 1인 합성곱을 이용하여 차원을 감소시키는 병목(Bottleneck) 구조를 구성
- ResNet
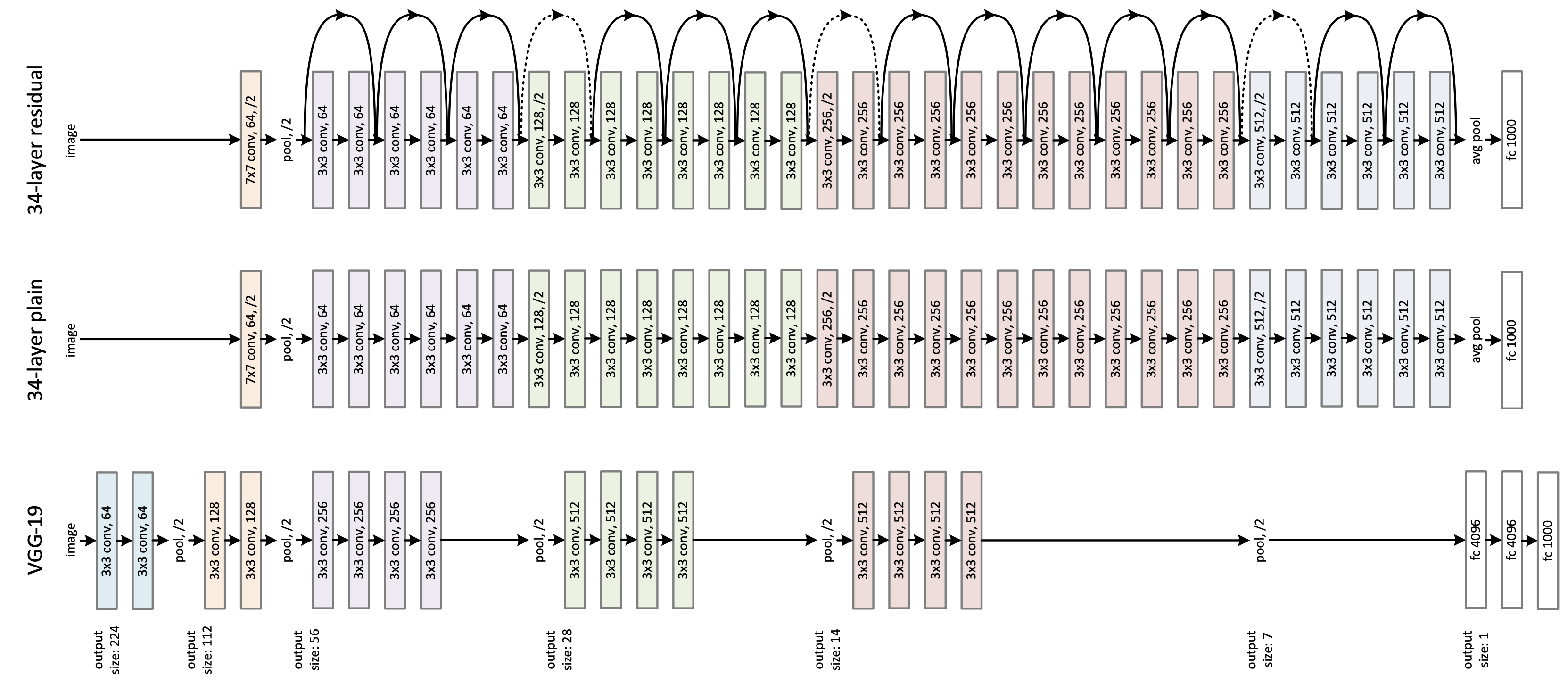
- CNN의 깊이가 깊어질 수록 성능이 향상되지만, 수백, 수천 개로 증가하면 오히려 정확도가 떨어지는 문제가 발생. 이러한 문제를 해결하기 위해 잔차 학습(Residual Learning)이라는 방법을 적용한 ResNet이 등장.
- 잔차 학습은 특정 층이 단순히 출력을 학습하는 것이 아니라 입력과 출력의 차이를 학습하여 작은 변화에 대해 민감하게 반응할 수 있도록 훈련하는 방법. 입력과 출력의 차이를 학습하게 되는 것은 덧셈(합)으로 구현되어 계산의 효율성도 유지 가능함.
- ResNet은 잔차 학습의 개념을 34개의 층으로 구성된 VGG에 적용시킨 모델로 정확도가 증가함.
- DenseNet
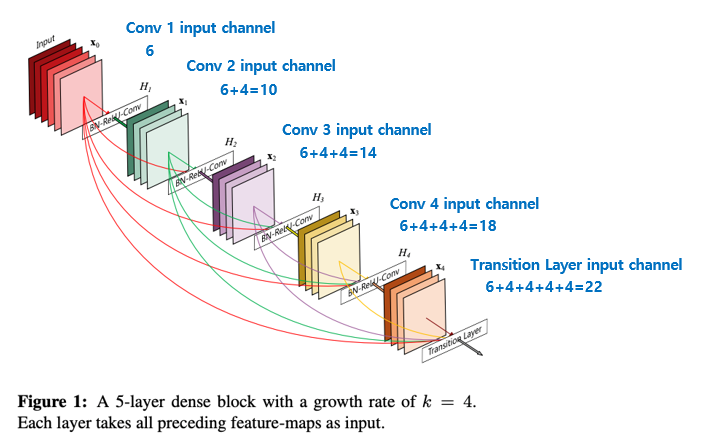
- AlexNet 등장 이후로 많은 모델 성능 향상을 위해 깊이를 증가시켰고, ResNet의 등장으로 깊이가 증가하면서 발생하는 문제를 해결함. 하지만, ResNet 이후로 모델의 구조 자체의 변화보다는 성능 향상만을 위한 연구가 진행됨. 이에 많은 모델은 특정 층들이 최종 출력에 기여하는 정도가 적거나 없어지는 문제가 발생.
- DenseNet은 ResNet 모델의 구조에 변화를 주어, ResNet의 층이 출력에 기여하지 않는 문제를 해결하여 성능을 향상시킴.
- DenseNet은 모든 층이 ResNet의 잔차 학습 방법으로 연결되어있는 구조. 모든 층의 출력은 각각의 후속 층의 입력으로 들어가며, ResNet과는 다르게 덧셈 연산을 하는 구조가 아닌 입력이 중첩되는 구조임(예를 들어 L번째 층은 L(L+1)/2개의 입력을 가짐).
- ResNet에 비해 더 적은 매개 변수를 가지기 때문에 더 빠른 학습이 가능함.
3. 객체 인식 기술 성능 비교
3.1. 객체 인식 방법 비교(Faster R-CNN, R-CNN, SSD)
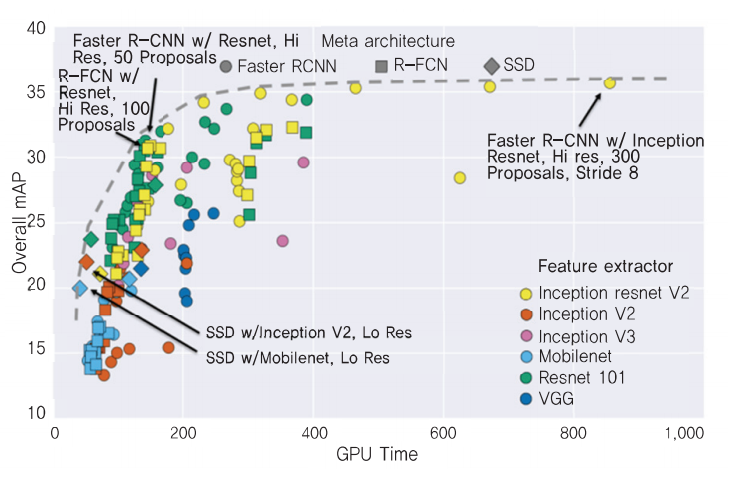
- R-FCN과 SSD는 훈련에 소요되는 시간은 비교적 적지만, 낮은 정확도
- Faster R-CNN은 훈련에 소요되는 시간은 비교적 많지만, 높은 정확도
3.2. CNN 모델에 따른 객체 인식 성능 비교
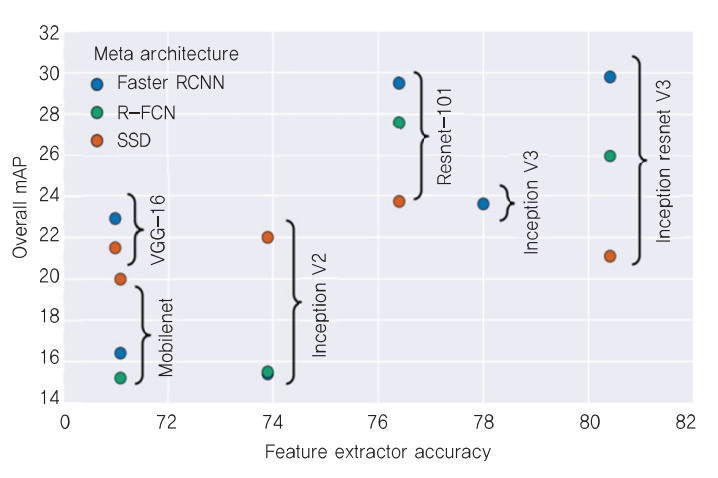
- ResNet-101과 Inception ResNet V2의 정확도가 가장 높음
3.3. 결론
- 현재의 객체 인식 기술은 특정 도메인에서의 객체 인식 정확도는 높지만, 일반적인 객체를 인식하는 데는 좋지 못함.
- 객체를 상자 형태로만 검출하는 것이 아니라, 정확한 픽셀 단위로 분할하는 연구가 이루어짐.
- 모바일 환경이나 다른 임베디드 시스템에 고성능의 딥러닝 기반 객체 인식 기술을 적용하기에는 아직 어려움이 많음.
- 따라서, 보다 단순한 구조의 객체 인식 방법과 가벼운 CNN 모델에 대한 연구가 진행되어야 함.