GoogleNet
-
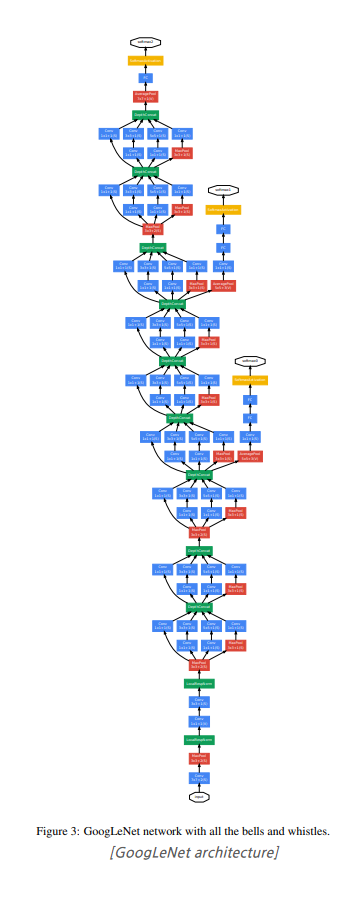
2014년 ILSVC 대회에서 1위를 한 모델이며, Google 연구팀이 개발하였다. 19층인 VGG19보다 좀 더 깊은 22층으로 구성되어 있다.
-
일반적인 CNN 구조는 feature extraction 부분(convolution layer + pooling layer)과 classifier 부분(fully connected neural network)으로 구성이 도니다. convolutional layer와 pooling layer를 번갈아 사용하는 layer를 여러 개 사용하여 feature를 추출하고, 최종 feature map을 classifier 역할을 하는 fully connected neural network를 이용하여 처리한다.
-
GoogLeNet의 구조를 알기 전에 NIN(Network in Network)의 구조와 설계 철학을 알고 들어가자. 왜냐하면 GoogLeNet을 개발한 구글은 자신들의 구조를 설계함에 있어 크게 2개의 논문을 참조하고 있으며, 그 중 Inception Module 및 전체 구조에 관련된 부분은 NIN 구조를 발전시킨 것이기 때문이다.
-
NIN 설계자는 CNN의 convolutional layer가 local receptive field(지역적인 수용 영역, mask filter)에서 feature를 추출하는 능력은 우수하지만, filter의 특징이 linear하기 때문에 non-linear한 성질을 갖는 feature를 추출하기엔 어려움이 있으므로, 이 부분을 극복하기 위해 feature map의 개수를 늘려야하는 문제에 주목했다. 하지만, 필터의 개수를 늘리게 되면 연산량이 늘어나는 문제가 있다. 따라서 NIN 설계자는 local receptive field 안에서 좀 더 feature를 잘 추출할 수 있는 방법을 연구하였으며, 이를 위해 micro neural network를 설계하였다. 이들은 convolution을 수행하기 위한 field 대신에 MLP를 사용하여 특징을 추출하도록 하였다.
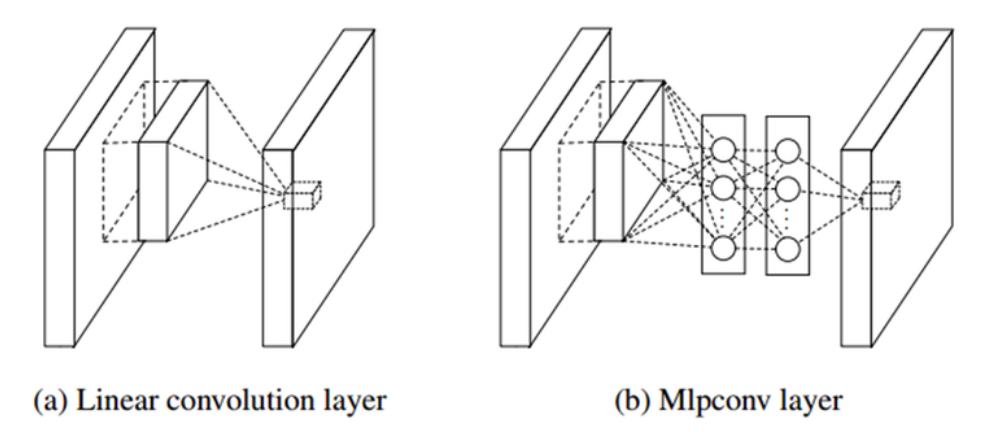
-
MLP를 사용하였을 때의 장점은 convolution kernel보다는 non-linear한 성질을 잘 활용할 수 있기 때문에 feature를 추출할 수 있는 능력이 우수하다는 점이다. 또한, 1x1 convolution을 사용하여 feature map을 줄일 수 있도록 하였으며, 이 기술을 Inception Module에 적용하였다.
-
NIN 구조가 기존 CNN과 또 다른 점은 CNN의 최종단에서 흔히 보이는 fully connected neural network가 없다는 점이다. 대신에 최종단에 global average pooling을 사용하였다. 이는 앞에 효과적으로 feature map을 추출하였기 때문에, 이렇게 추출된 map에 대한 pooling만으로도 충분하다고 주장하고 있다. 즉, average pooling만으로 classifier 역할을 할 수 있기 때문에 overfitting의 문제를 회피할 수 있고, 연산량이 대폭 줄어드는 이점도 얻을 수 있다.
-
CNN의 최종단에 있는 fully connected NN은 전체 free parameter 중 90% 수준에 육박하기 때문에, 많은 파라미터의 수로 인해 overfitting에 빠질 가능성이 아주 높으며, 이를 피하기 위해선 Dropout 기법을 적용해야 한다. 하지만 NIN의 경우는 average pooling만으로 classification을 수행할 수 있기 때문에 overfitting에 빠질 가능성이 현저하게 줄어들게 된다.
-
이러한 NIN 구조는 GoogLeNet 모델의 ‘네트워크 안의 네트워크’라는 구조에 영향을 많이 끼친 구조라고 할 수 있다.
1. 특징
1) 1x1 Convolution
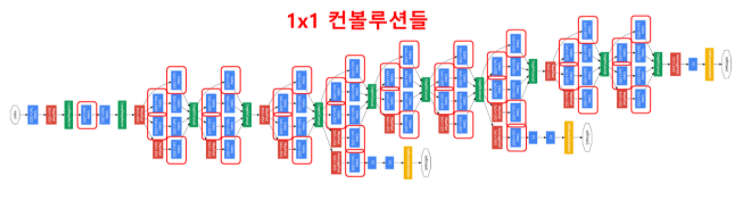
-
위의 구조도를 보면 곳곳에 1x1 필터의 convolution 연산이 있음을 확인할 수 있다.
-
1x1 convolution은 feature map의 개수를 줄이는 목적으로 사용된다. feature map을 줄일수록 연산량이 줄어들 수 있기 때문이다.
-
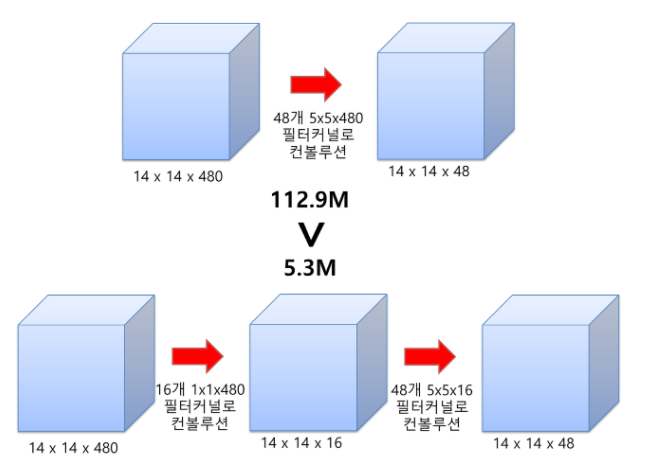
예를 들어, 480장의 14x14의 feature map을 48장의 14x14로 줄여보도록 하자. 첫 번째 방법은 1x1 convolution을 사용하지 않고, 5x5 필터로 convolution 연산을 해주자. 이때 필요한 연산횟수는 (14x14x48) x (5x5x480) = 112.9M이 된다. 두 번째 방법은 16개의 1x1x480의 필터로 convolution 연산을 해보자. 결과적으로 16장의 14x14의 feature map이 산출된다. 다시 이 14x14x16 feature map을 48개의 5x5x16의 필터로 convolution 연산을 해주면 48장의 14x14 feature map으로 줄어들 수 있다. 그럼 이때 필요한 연산횟수는 (14x14x16) x (1x1x480) + (14x14x48) x (5x5x16) = 5.3M이다. 첫 번째 방법에 비해 훨씬 많은 연산량을 줄일 수 있다.
2) Inception Module
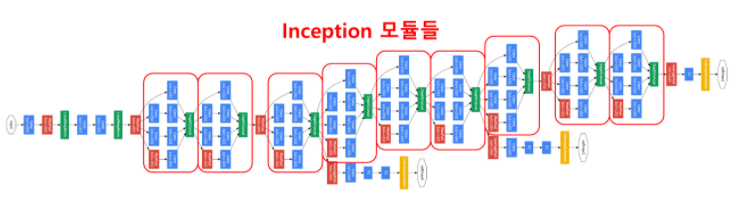
- GoogLeNet은 총 9개의 inception module을 포함하고 있다. 기존에는 layer간에 1 convolution + 1 pooling 연산으로 연결하였다면, inception module은 총 4가지 서로 다른 연산을 거친 뒤 feature map을 channel 방향으로 합치는 concatenation을 이용하고 있다는 점이다.

-
위의 구조에서 노란색 블럭으로 표현된 1x1 convolution을 제외하고, 3x3, 5x5 convolution 연산을 섞어서 사용하는 방식을 Naive Inception Module이라고 부른다. 또한, 여기에 추가로 3x3 convolution와 5x5 convolution 연산이 많은 연산량을 차지하고 있기 때문에, 두 convolution 연산 앞에는 1x1 필터를 적용한 convolution 연산을 추가하여 feature map의 개수를 줄이고, 다시 거꾸로 3x3, 5x5 convolution 연산을 수행하여 feature map을 키워주는 bottleneck 구조를 추가하였다.
-
AlexNet, VGGNet 등의 이전 CNN 모델들은 하나의 layer에 동일한 사이즈의 필터를 이용해서 convolution 연산을 해줬던 것과는 차이가 있다. 따라서 Inception module 덕분에 다양한 종류의 특성이 도출될 뿐만 아니라, 연산량이 절반 이상을 줄일 수 있었다.
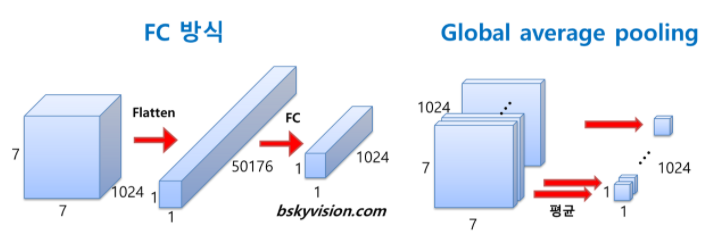
3) Global Average Pooling
- AlexNet, VGGNet 등에서는 FC layer들이 망의 후반부에 연결되어 있다. 하지만 GoogLeNet FC 방식 대신에 global average pulling이란 방식을 사용한다. global average pooling은 전 층에서 산출된 feature map들을 각각 평균낸 것을 이어서 1차원 벡터를 만들어주는 것이다. FC layer와 같이 1차원 벡터로 만들어주어야 최종적으로 이미지 분류를 위한 softmax 함수로 연결할 수 있기 때문이다.
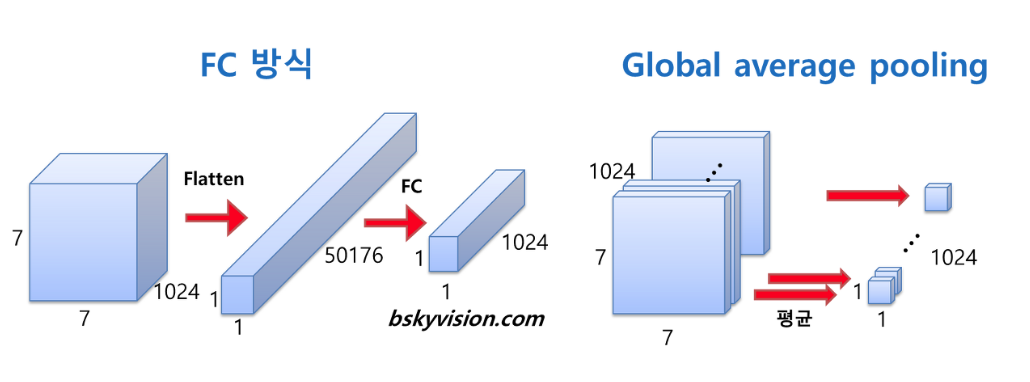
- 이 방식을 통해 가중치의 개수를 상당히 많이 없애줄 수 있다. 만약 FC 방식을 사용한다면 훈련이 필요한 가중치의 개수가 7x7x1024x1024=51.3M이지만, global average pooling을 사용하면 가중치가 단 한 개도 필요하지 않다. 이러한 방식 덕분에 AlexNet, ZFNet, VGGNet 등에 비해 훨씬 적은 수의 파라미터를 가질 수 있다.
4) Auxiliary Classifier
-
네트워크의 깊이가 깊어질수록 Back Propagation 과정에서 가중치를 업데이트하는데 사용되는 gradient가 점점 작아져서 0이 되어버리는 Vanishing Gradient 문제가 발생하며, 이로 인해 학습 속도가 아주 느려지거나 overfitting 문제가 발생한다. gradient 값들이 0 근처로 가게 되면, 학습 속도가 느려지거나 파라미터의 변화가 별로 없어 학습 결과가 나빠지는 현상이 발생하기 때문이다.
-
최근의 DNN에서는 activation function을 주로 ReLU를 사용하는데, sigmoid나 cross-entropy를 사용할 때보다 많은 이점이 있기 때문이다. 하지만 여러 layer를 거치면서 작은값들이 계속 곱해지다 보면, 0 근처로 수렴되면서 역시 vanishing gradient 문제에 빠질 수 있고, 망이 깊어질수록 이 가능성이 커진다. 따라서 네트워크 내의 가중치들이 제대로 훈련되지 못하는데, 이 문제를 극복하기 위해서 GoogLeNet은 네트워크 중간에 두 개의 보조 분류기(Auxiliary Classifier)를 달아주었다.

- 위의 그림에서 왼쪽은 보조 분류기가 없는 경우에 iteration이 커질수록 grdient가 현저하게 작아지는 것을 보여주며, 오른쪽은 보조 분류기가 없는 경우는 파란색 점선, 보조 분류기가 있는 경우는 빨간색 실선으로 표시된다. 보다시피 빨간색 실선이 gradient 값이 다시 증가하게 되면서, 보다 더 안정적인 학습 결과를 얻을 수 있다.

-
이 보조 분류기들로 구한 loss는 보조적인 역할을 맡고 있으므로, 기존 가장 뒷 부분에 존재하던 classifier보단 전체적으로 적은 영향을 주기 위해 0.3을 곱해 total loss에 더하는 식으로 사용했다고 한다.
-
학습 단계에서만 사용이 되고 테스팅 단계에선 사용이 되지 않았는데, 그 이유는 테스팅시에 성능 향상이 미미하기 때문이다.
2. 구조
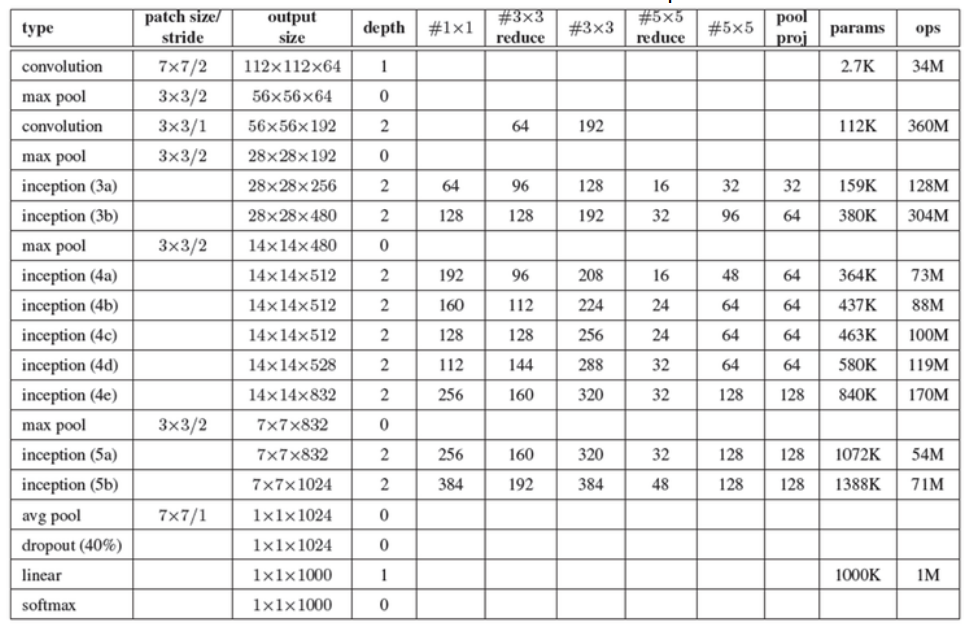
- patch size / stride
- kernel의 크기와 stride의 간격을 말한다. 최초의 convolution에 있는 7x7/2의 의미는 receptive field의 크기가 7x7인 filter를 2픽셀 간격으로 적용한다는 뜻이다.
- output size
- 산출되는 feature map의 크기 및 개수를 나타낸다. 112x112x64의 의미는 224x224 크기의 이미지에 2픽셀 간격으로 7x7 필터를 적용하여 총 64개의 feature map이 얻어졌다는 뜻이다.
- depth
- 연속적인 convolution layer의 개수를 의미한다. 첫 번째 convolution layer는 depth가 1이고, 두 번째와 inception이 적용되어 있는 부분은 모두 2로 되어 있는 이유는 2개의 convolution을 연속적으로 적용하기 때문이다.
- 1x1
- 1x1 convolution을 의미하며, 그 행에 있는 숫자는 1x1 convolution을 수행한 뒤 얻어지는 feature map의 개수를 말한다.
- 3x2 reduce
- 3x3 convolution 앞쪽에 있는 1x1 convolution을 의미하며 마찬가지로 inception (3a)에 있는 수를 보면 96이 있는데, 이것은 3x3 convolution을 수행하기 전에 192차원을 96차원으로 줄인 것을 의미한다.
- 3x3
- 1x1 convolution에 의해 차원이 줄어든 feature map에 3x3 convolution을 적용한다. inception (3a)에 있는 숫자 128은 최종적으로 1x1 convolution과 3x3 convolution을 연속적으로 적용하여 128개의 feature map을 얻었다는 뜻이다.
- 5x5 reduce
- 3x3 reduce와 동일한 방식이다.
- 5x5
- 3x3과 동일한 방식이다.
- pool / proj
- max pooling과 max pooling 뒤에 오는 1x1 convolution을 적용한 것을 의미한다. inception (3a) 열에 있는 숫자 159K는 총 256개의 feature map을 만들기 위해 159K의 free parameter가 적용되었다는 뜻이다.
- Ops
- 연산의 수를 나타낸다. 연산의 수는 feature map의 수와 입출력 feature map의 크기에 비례한다. inception (3a)의 단계에서 총 128M의 연산을 수행한다.
3. 중요한 점
- 효과적으로 grid의 크기를 줄이는 방법
1) 단순히 pooling layer를 적용하는 것보다, inception module과 같이 나란히 적용하는 것이 효과적이다.
2) 사이즈가 큰 kernel 대신에 convolution kernel에 대한 인수분해 방식을 적용하고, 앞뒤 일부 구조 및 feature map의 개수를 조정하는 것만으로도 같은 사이즈의 결과를 가져오고, 성능도 상당히 개선시킬 수 있다.
4. 참고자료
Deep Learning Image Classification Guidebook [1] LeNet, AlexNet, ZFNet, VGG, GoogLeNet, ResNet