VGGNet
2014년 ILSVRC에서 GoogLeNet과 함께 큰 주목을 받으며, 준우승을 차지한 모델이다. 준우승이었지만, 구조적인 측면에서 GoogLeNet보다 훨씬 간단한 구조로 되어 있으며, 향후 모델의 발전 역사에서 VGGNet 모델부터 시작해서 네트워크의 깊이가 확 깊어졌다.
- Depth
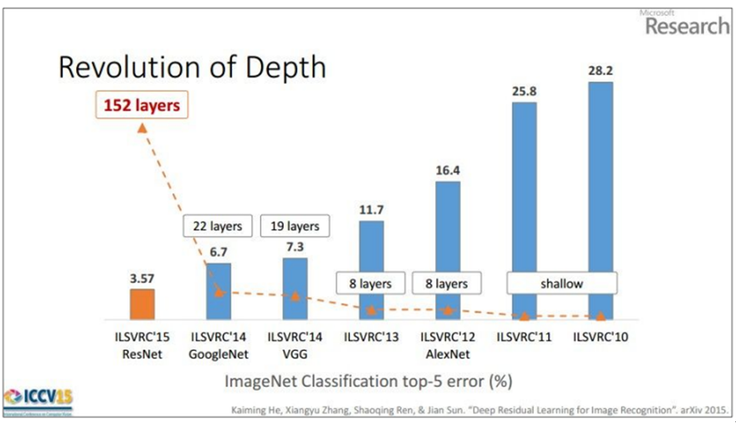
- VGGNet이 발표되기 전까지만해도 AlexNet이나 ZFNet과 같은 대부분의 모델은 8 layer의 수준이었다. 하지만 GoogLeNet과 VGGNet 모두 이전 구조에 비해 훨씬 deep해진다.
-
VGGNet의 연구팀은 origin 논문 Very deep convolutional networks for large-scale image recognition에서 밝히듯이 원래는 depth가 딥러닝 모델에 어떤 영향을 주는지 연구를 하기 위해 VGGNet을 개발한 것 같다.
-
따라서 깊이의 영향만을 최대한 확인하고자, convolution 필터 커널의 사이즈는 가장 작은 3x3으로 고정했다. 만약 필터 사이즈의 크기가 크게 되면, 그만큼 이미지의 사이즈가 축소되기 때문에 네트워크의 깊이를 충분히 깊게 만들기 어렵기 때문이다.
-
총 6개의 구조(A, A-LRN, B, C, D, E)를 만들어 성능을 비교했다. 여러 구조를 만든 이유는 기본적으로 깊이의 따른 성능 변화를 비교하기 위함이다.
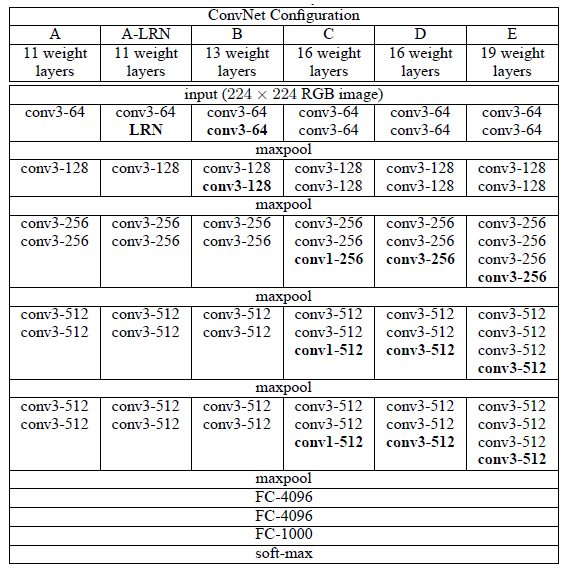
- 진행했던 연구를 보면, AlexNet에서 사용되던 LRN은 A와 A-LRN 구조의 성능을 비교해보면서 성능 향상에 효과가 없다는 것을 밝혔다. 그래서 더 깊은 구조인 B, C, D, E에서는 LRN을 적용하지 않는다.
- Filter
- VGGNet의 구조를 파악하기 전에 먼저 집고 넘어가야 하는 것이 바로 3x3 필터를 사용하는 것이다. 3x3 필터를 2번 convolution 연산을 하는 것과 5x5 필터를 1번 convolution 연산을 하는 것이 결과적으로 동일한 사이즈의 feature map을 산출한다는 것이 핵심이다. 만약 3x3 필터로 3번 convolution 연산을 한다면, 7x7 필터로 1번 convolution 연산을 하는 것과 대응된다.
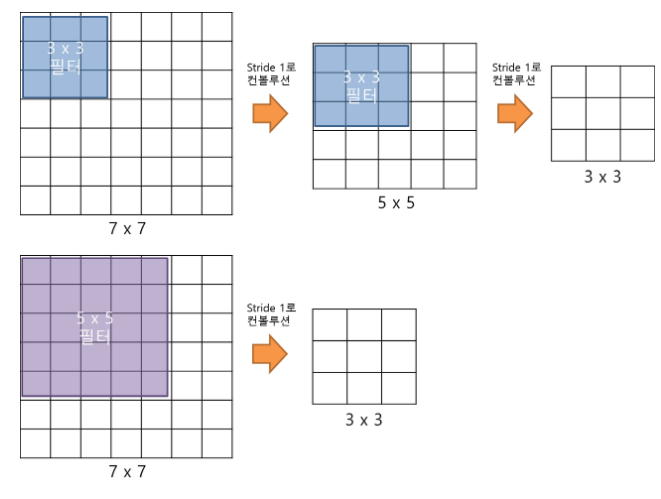
- 그렇다면 3x3 필터로 3번 convolution하는 것이 7x7 필터로 1번 convolution 연산을 하는 것보다 나은 점은 무엇인가? 바로, 가중치 또는 파라미터의 수의 차이다. 3x3 필터가 3개면 총 27개의 가중치를 가지는 반면, 7x7 필터는 1개만이어도 총 49개의 가중치를 가진다. CNN에서 가중치는 training에서 사용되는 파라미터이기 때문에, 학습 속도에 영향을 준다. 즉, 사용되는 파라미터의 개수가 적어질수록 학습 속도가 빨라진다는 것이다. 동시에 layer의 개수 역시 늘어나지면서 feature에 비선형성을 증가시켜주어 feature가 점점 더 유용해진다.
-
위에서 나오는 feature에 비선형성을 증가시켜주는 것이 좋다는 이유를 알아보자. 만약 Neural Network에서 activation function을 linear function을 사용하면 신경망의 depth를 깊게 하는 의미가 사라진다. activation function이 h(x)=cx인 선형함수라고 가정할 때, 3층 네트워크가 되면 y(x)=h(h(h(x)))가 되는데 이는 y(x)=ccc*x가 된다. 이는 y(x)=ax라는 linear한 구조이기 때문에, 여러 층을 구성하는 이점을 살릴 수 없다.
-
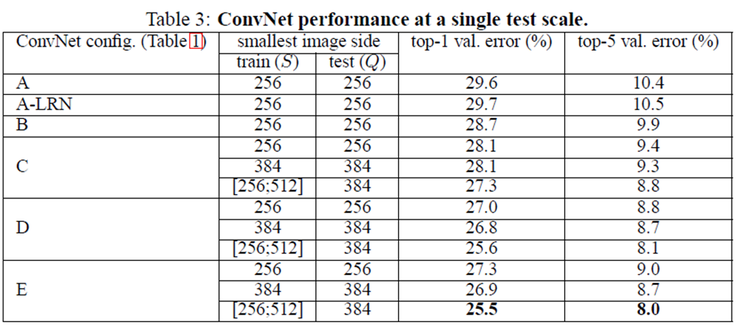
B 구조는 3x3 convolution layer를 2번 사용하는 경우와 5x5 convolution layer를 1번 사용하는 모델을 만들어 실험을 했는데, 결과는 3x3 필터를 2번 사용하는 경우가 5x5 필터를 1번 사용하는 것보다 top-1 error에서 7% 성능을 높일 수 있었다.
1. 특징
- LRN을 적용하지 않는다.
- 학습 parameter의 수를 적게 만들고, depth의 깊이를 늘리기 위해 3x3 필터를 사용한다.
2. 구조
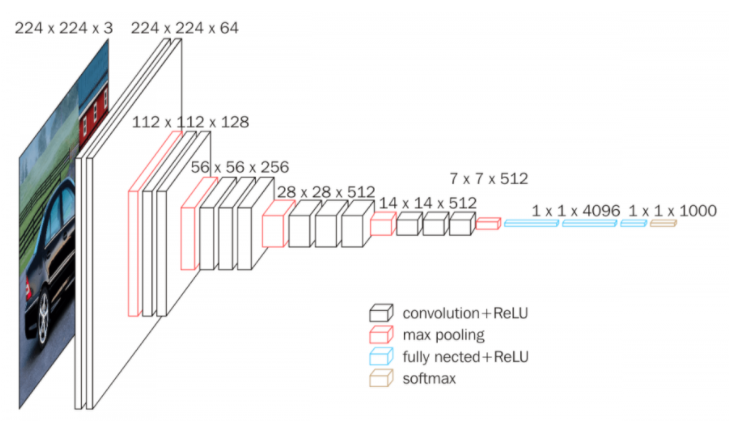
-
input layer에서는 224x224 사이즈의 컬러 이미지를 입력받는다(224x224x3)
-
첫 번째 레이어에서 convolution layer에서 64개의 3x3x3 필터로 입력 이미지를 convolution 연산을 해준다. stride=1, zero padding=1로 설정해준다. 이 두 개의 하이퍼파라미터는 다음 모든 convolution layer에서 동일하게 적용한다. 결과적으로 64장의 224x224x64의 feature map을 산출한다. activation function은 ReLU를 사용하였고, 마찬가지로 output layer를 제외하고 모든 convolution layer에서 동일하게 적용한다.
-
두 번째 레이어에서 convolution layer에서 64개의 3x3x64 필터로 convolution 연산을 해주어, 결과적으로 224x224x64의 feature map이 산출된다. pooling layer에서는 2x2 필터로 stride=2로 적용하여 max pooling을 하여, 결과적으로 feature map의 사이즈를 112x112x64로 줄인다.
-
세 번째 레이어에서부터는 AlexNet과 비슷한 맥락으로 진행한다. 자세하게 살펴보려면 VGGNet의 구조 (VGG16)로 GoGo..
-
VGGNet은 AlexNet이나 ZFNet처럼 224x224 크기의 컬러 이미지를 입력으로 받아들이고, 1개 혹은 그 이상의 convolutional layer 뒤에 max pooling layer가 오는 단순한 구조가 되어 있다. 또한, 맨 마지막 단에는 fully connected layer가 온다. 이러한 구조 덕분에 간단하고 이해나 변형이 쉬운 장점을 가지고 있지만, 파라미터의 수가 엄청나게 많기 때문에 학습 시간이 오래 걸린다.
3. 참고자료
Deep Learning Image Classification Guidebook [1] LeNet, AlexNet, ZFNet, VGG, GoogLeNet, ResNet