LeNet
MLP가 가지는 한계점인 input의 픽셀수가 많아지면 parameter가 기하급수적으로 증가하는 문제를 해결할 수 있는 CNN 구조 제시하였다.
1. 특징
- input을 2차원으로 확장하였고, parameter sharing을 통해 input의 픽셀 수가 증가해도 parameter 수가 변하지 않는다는 특징을 가지고 있다.
2. 구조
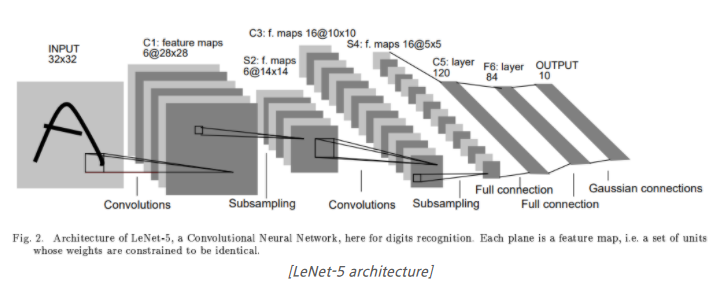
-
C1 layer에서는 32x32 픽셀의 image를 input으로 사용하고, 6개의 5x5 필터와 convolution 연산을 해준다. 그 결과, 6장의 28x28 feature map을 산출한다.
-
S2 layer에서는 C1 layer에서 출력된 feature map에 대해 2x2 필터를 stride=2로 설정하여 sub sampling을 진행한다. 그 결과, 14x14 feature map으로 축소된다. sub sampling 방법은 average pooling 기법을 사용하였는데, original 논문인 Gradient-Based Learning Applied to Document Recognition에 따르면, 평균을 낸 후에 한 개의 trainable weight을 곱해주고, 또 한 개의 trainable bias를 더해준다고 한다. activation function은 sigmoid를 사용한다.
-
C3 layer에서는 6장의 14x14 feature map에 convolution 연산을 수행해서 16장의 10x10 feature map을 산출한다.
-
S4 Layer에서는 16장의 10x10 feature map에 sub sampling을 진행해 16장의 5x5 feature map으로 축소시킨다.
-
C5 layer에서는 16장의 5x5 feature map에 120개의 5x5x16 필터를 convolution 연산을 수행해서 120장의 1x1 feature map을 산출한다.
-
F6 layer는 84개의 유닛을 가진 Feed Forward Neural Network로, C5 layer의 결과를 연결시켜준다.
-
Output layer는 10개의 Euclidean radial Bias Function(RBF) 유닛으로 구성되어 F6 layer의 결과를 받아서, 최종적으로 이미지가 속한 클래스를 분류한다.
3. 참고자료
Deep Learning Image Classification Guidebook [1] LeNet, AlexNet, ZFNet, VGG, GoogLeNet, ResNet
AlexNet
LeNet-5와 구조가 크게 다르지 않으며, 2개의 GPU로 병렬연산을 수행하기 위해 병렬적인 구조로 설계되었다. 왜냐하면 그 당시에 사용한 GPU인 GTX 580이 3GB의 VRAM을 가지고 있는데, 하나의 GPU로 사용하기엔 메모리가 부족하기 때문이다.
1. 특징
- Multiple GPU Training
-
activation function은 ReLU를 사용하였다. tanh보다 빠르게 수렴하는 효과를 얻을 수 있다고 한다.
-
normalization은 Local Response Normalization(LRN)을 사용하였고, Pooling의 커널 사이즈를 stride보다 크게 하는 Overlapping Pooling을 사용하였다. 이외에도 Dropout, PCA를 이용한 data augmentation 기법을 사용하였다.
- Dropout
-
overfitting을 막기 위한 regularization 기술의 일종으로, fully connected layer의 뉴런 중 일부를 생략하면서 학습을 진핸한다. 즉, 몇몇의 뉴런의 값들을 0으로 바꾸어 forward 및 backward propagation에 영향을 주지 못한다.
-
dropout은 train에만 적용되고, test에는 모든 뉴런을 사용한다.
-
- Overlapping Pooling
-
CNN에서 pooling은 feature map의 크기를 줄이는 역할로, 보통 average pooling과 max pooling 2가지를 사용한다. average pooling은 sliding window에 걸려있는 값 중 평균값을 선택하고, max pooling sliding window에 걸려있는 값 중 최대값을 선택한다.
-
pooling시에는 통상적으로 겹치는 값이 없게 하지만, original 논문인 ImageNet Classification with Deep Convolutional Neural Networks에서는 max pooling을 사용하면서 크기를 3으로, stride를 2로 주어 sliding이 겹치는 부분이 발생한다(overlapping pooling).
-
LeNet의 경우 average pooling을 사용하였지만, AlexNet에서는 max pooling을 사용하였다. 또한, AlexNet의 경우 pooling kernel이 움직이는 보폭인 stride를 커널 사이즈보다 작게하는 overlapping pooling을 적용하였다.
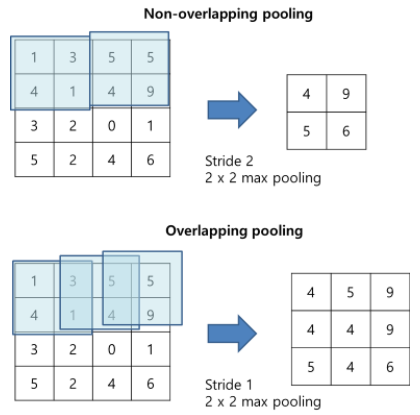
- overlapping pooling을 하면 중첩이 되면서 진행하지만, non-overlapping pooling을 하면 중첩이 되지 않는다. original 논문은 overlapping pooling을 하면 top-1, top-5 error를 줄이는데 효과가 있다고 한다.
-
- Local Response Normalization(LRN)
-
활성화된 뉴런이 주변 이웃 뉴런들을 억누르는 현상을 lateral inhibition 현상이라고 하며, 이를 모델링한 것이 LRN이다. 강하게 활성화된 뉴런의 주변 이웃들에 대해서 normalization을 실행한다. 주변에 비해 어떤 뉴런이 비교적 강하게 활성화되어 있다면, 그 뉴런의 반응은 더욱더 돋보일 것이다. 반면에 강하게 활성화된 뉴런 주변도 모두 강하게 활성화되어 있다면, LRN 이후에는 모두 값이 작아질 것이다.
-
이러한 LRN은 ReLU 활성화 함수를 처리하는데 유용하다. 만약 ReLU를 통해 활성화된 뉴런이 여러개가 있으면, 정규화를 위해 LRN이 필요하기 때문이다.
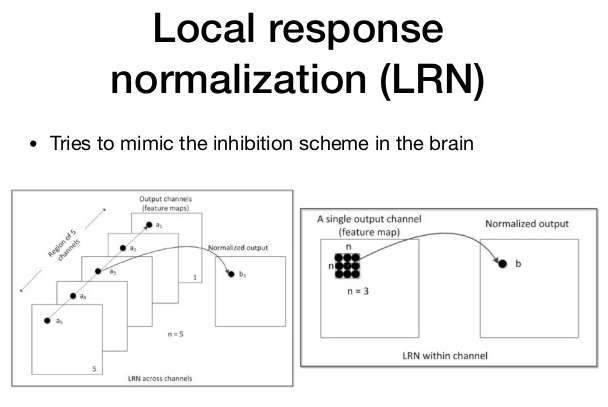
- original 논문에서는 top-1, top-5에서 각각 1.4%, 1.2%의 성능 향상이 발생하였다. 하지만 이 방법은 지금에 와서는 성능상의 이점이 없어 잘 사용하지 않는다.
-
- Data Augmentation
- overfitting을 막기 위한 dropout과 같은 regularization의 방법이다. overffiting을 막기 위한 가장 좋은 방법은 데이터의 양을 늘리는 것인데, 하나의 이미지를 가지고 여러 장의 비슷한 이미지를 만들어내면서 데이터의 양을 늘릴 수 있다. 즉, 같은 내용을 담고 있지만 위치가 살짝 다른 이미지들이 생산된다.
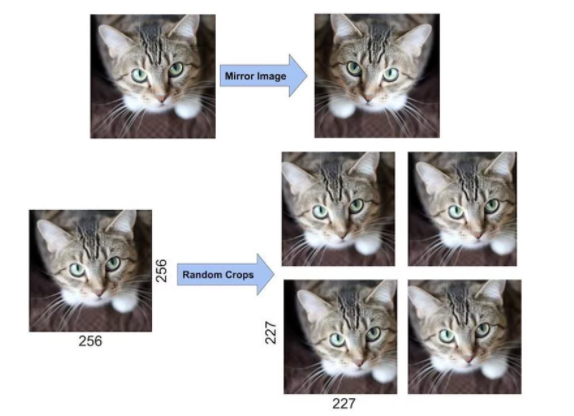
- Dropout
2. 구조
-
AlexNet은 8개의 layer로 구성되어 있다. 5개의 convolution layer와 3개의 fully connected layer로 구성되어 있다.
-
input layer에는 224x224 사이즈의 RGB 컬러 이미지가 입력된다(224x224x3)
-
첫 번째 레이어에서 convolution layer는 96개의 11x11x3 사이즈의 필터로 convolution 연산을 한다. stride=4로 설정, padding은 사용하지 않아 결과적으로, 55x55x96 feature map이 산출된다. convolution layer는 항상 activation function이 붙어있기 때문에, ReLU를 사용하여 활성화해준다. pooling layer는 3x3 overlapping max pooling을 stride=2로 시행하여 결과적으로, 27x27x96 feature map을 산출한다.
-
두 번째 레이어에서 convolution layer는 256개의 5x5x48 사이즈의 필터로 convolution 연산을 한다. stride=1로 설정, padding=2로 설정하여 결과적으로, 27x27x256 feature map이 산출된다. activation function 역시 ReLU로 활성화한다. pooling layer도 마찬가지로 3x3 overlapping max pooling을 stride=2로 시행하여 결과적으로, 13x13x256 feature map을 산출한다. 첫 번째 레이어와 다르게, local response normalization을 시행하여 feature map이 유지된다.
-
세 번째 레이어에서 convolution layer는 384개의 3x3x256 사이즈의 필터로 convolution 연산을 한다. stride=1로 설정, padding=1로 설정하여 결과적으로, 13x13x384 feature map을 얻게 된다. activation function 역시 ReLU로 활성화한다.
-
네 번째 레이어에서 convolution layer는 384개의 3x3x192 사이즈의 필터로 convolution 연산을 한다. stride=1로 설정, padding=1로 설정하여 결과적으로 13x13x384 feature map을 얻게 된다. activation function 역시 ReLU로 활성화한다.
-
다섯 번째 레이어는 네 번째 레이어와 동일하게 activation까지 진행하며, pooling layer에서 3x3 overlapping max pooling을 stride=2로 시행하여 결과적으로, 6x6x256 feature map을 산출한다.
-
여섯 번째 레이어는 fully connected layer로, 6x6x256 feature map을 flatten해주어 6x6x256=9216 차원의 벡터로 변환한다. 이를 여섯 번째 레이어의 4096개의 뉴런과 연결시키고, 그 결과를 ReLU로 활성화해준다.
-
일곱 번째 레이어도 fully connected layer로, 4096개의 뉴런을 가지고 있으며, 여섯 번째 레이어와 동일하게 진행한다.
-
여덟 번째 레이어도 fully connected layer로, 1000개의 뉴런을 가지고 있으며, 일곱 번째 레이어와 연결하여 softmax function을 적용해 확률을 구한다.
3. 참고자료
Deep Learning Image Classification Guidebook [1] LeNet, AlexNet, ZFNet, VGG, GoogLeNet, ResNet