논문 내용 정리
Abstract
- object detection과 sementic segmentation과 같은 domain application에 적용하여 image classification 정확도를 향상시키는 것을 증명할 것이다.
1. Introduction
- 모델의 architecture를 향상시키기 위해서는 loss function을 변경하고, data 전처리와 optimization methods가 주요한 역할을 한다.
- 이전까지의 논문에서는 단순히 convolution layer의 stride 사이즈 조정이나 learning_rate의 schedule 조정에만 그치는 minor한 tricks를 사용했다.
- 하지만 본 논문에서는 경험적인 실험을 통해, 정확도 향상의 주요한 역할을 한 몇 가지 “tricks”를 사용한 것과 그들을 함께 binding하여 모델의 정확도를 더욱 가속시켜주는 것을 보여줄 수 있다.
- Section 2에서는 baseline training 절차를, Section 3에서는 몇 가지 “tricks”가 어떻게 하드웨어에서 효율적인 훈련을 할 수 있는지를 다뤄볼 것이다. 그리고 Section 4에서는 ResNet에 3개의 minor한 모델 구조 변경을 해볼 것이고, Section 5에서는 추가적으로 4개의 training procedure refinements에 대해 다뤄볼 것이다. 마지막으로, Section 6에서 transfer learning을 통해 본 연구가 모델의 정확도를 얼마나 향상시켰는지 보여줄 것이다.
2. Training Procedures
- mini-batch SGD와 일반적인 전처리 과정을 통해 모델을 학습시켰다.
3. Efficient Training
- 학습 효율성 증가
-
단일 머신러닝 훈련을 위한 batch size를 조정하기 위해 4개의 heuristic을 사용한다.
1) Linear scaling learning rate
- mini-batch SGD에서 batch size를 증가시키는 것은 SGD의 기댓값을 바꾸지는 못하지만, 분산을 줄여준다.
- 다른 말로 batch size가 크게 되면, graident에 있는 noise를 줄여주기 때문에 learning_rate를 증가시켜야만 한다.
- 즉, batch size가 커지면 learning_rate도 크게, batch size가 작아지면 learning_rate도 작게 만들어주는 것이 좋다.2) Learning rate warmup
- 처음 시작하는 training은 모든 파라미터들이 랜덤으로 설정되어 있기 때문에, 정답(우리가 목표로 하는)에서 멀어져 있다. 그렇다고 learning_rate를 크게 잡아버리면 수치적으로 불안정해진다.
- 따라서, 처음에는 learning_rate를 작게 잡고 trainig process가 안정적이게 되면 learning_rate를 바꿔준다.3) Zero gamma
- ResNet network는 multiple residual blocks로 구성되어 있는데, 이 residual blocks는 입력과 출력의 잔차를 학습하는 지름길이다.
- 각각의 block들은 convolutional layer로 이루어져 있다. 이때, 마지막 block의 layer인 Batch Normalization(BN) Layer에서 x와 곱해지는 값인 gamma는 beta와 마찬가지로 학습할 수 있는 learnable parameter이므로, 학습 전에 초기화를 시켜주어야 한다.
- gamma가 0이면, back propagation을 발생하지 않게 해주며 이는 학습 초기 단계의 안정성을 높여준다.4) No bias decay
- weight decay는 overfitting이 발생하지 않도록, weight값을 decay해주는 기법이다.
- Highly scalable deep learning training system with mixed-precision: Training imagenet in four minutes.의 논문에 따르면, weight에만 decay를 주는 것이 overfitting을 방지할 수 있다고 한다. - precision을 감소시킨 training(FP32 -> FP16)을 통해 연산량의 속도를 증가시킬 수 있다. 하지만, 수를 표현할 수 있는 범위가 줄게되어 학습 성능이 저하될 수 있는데, 이를 해결하기 위해 Mixed precision training 방식을 적용하여 학습을 시킨다.
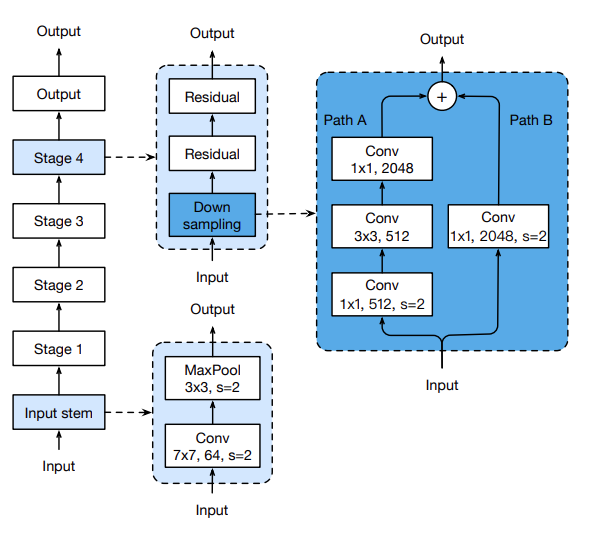
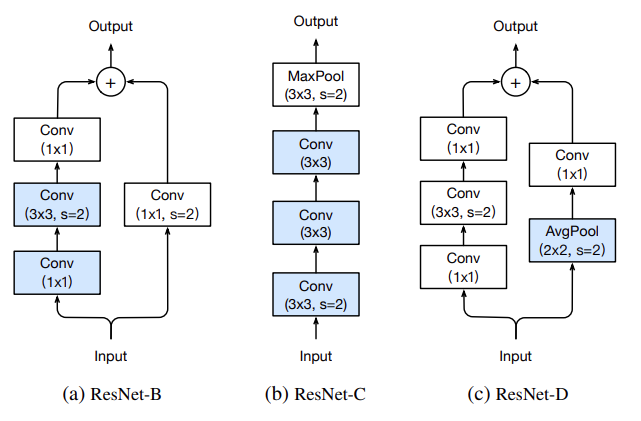
4. Model Tweaks
- 모델 구조 수정
- ResNet 구조에서 약간의 모듈들을 수정하여 성능을 올리는 방법을 제시한다.
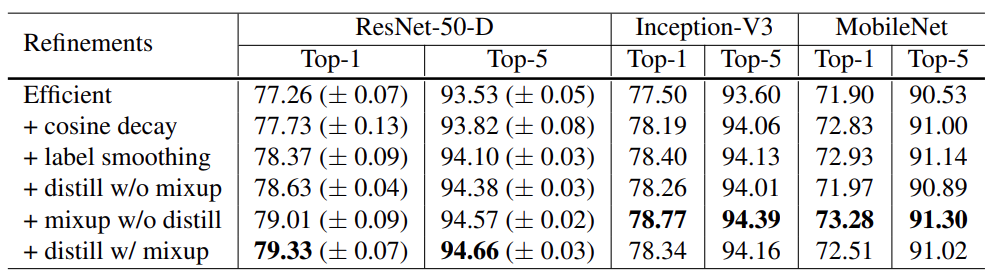
5. Training Refinements
-
정확도 증가를 위한 4가지 학습 방법
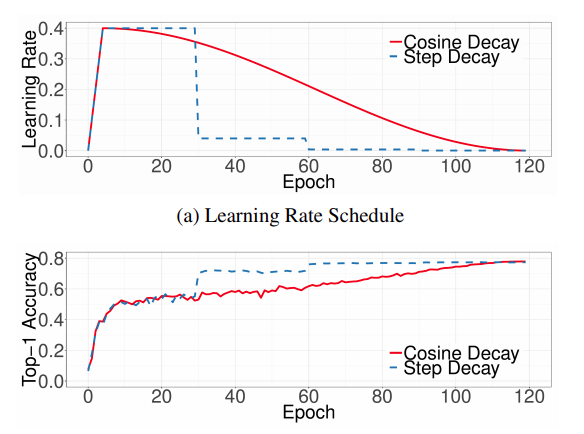
1) Cosine Learning Rate Decay + 인위적으로 learning_rate를 설정하는 것보다, 연속적으로 조금씩 바꾸는 것이 성능을 향상시킬 수 있다.
2) Label Smoothing + 모델의 성능 평가는 데이터셋의 label과 image classification 모델의 output layer를 통해 나온 결과와 비교한다. + 이 label의 결과를 2가지 방식으로 표현할 수 있는데, 예를 들어 개, 고양이, 곰을 분류하고자 하자. + 첫 번째 방식은 one-hot vector와 같이 [0, 1, 0]로 표현하는 hard한 방식으로, 1값의 위치에 놓인 결과를 단정한다. + 두 번째 방식은 확률 기반으로 [0.3, 0.6, 0.1]로 표현하는 smooth한 방식으로, 어느 정도의 오차를 반영한다.
3) Knowledge Distillation + Distilling the Knowledge in a Neural Network 논문에서 제안한 방법으로, 성능이 좋은 teacher model을 이용하여 student model이 적은 연산 복잡도를 가지면서 teacher model의 정확도를 따라가도록 학습 시키는 방법이다.
4) Mixup Training + mixup: BEYOND EMPIRICAL RISK MINIMIZATION 논문에서 제안한 방법으로, 데이터에 독립적인 이미지를 붙이는 기법으로 두 데이터의 이미지와 label을 각각 weighted linear interpolation하여 새로운 이미지를 생성하는 augumentation 기법을 의미한다. + opencv에서 배운 영상 모핑 과정에서 단순히 이미지를 합성하는 것이 아니라, label의 값도 표현할 수 있도록 한다.
6. Transfer Learning
- 전이 학습
- 자신의 모델을 FN Layer를 떼어내고 그 자리에 붙여 모델의 성능을 평가한다.
- Object Detection과 Semantic Segmentation에 적용하여 성능이 좋아지는지 실험을 수행한다.
Conclusion
- ResNet-50, Inception-V3, MobileNet에서 경험적인 실험을 통해, 이러한 “tricks”가 모델의 정확도를 지속적으로 향상시킴을 증명하였다.
- 또한, 이들을 모두 함께 stacking(개별 모델이 예측한 데이터를 다시 train set으로 사용해서 학습)하여 더 높은 정확도를 만들 수 있는 중요한 사실을 발견하였다.
새롭게 알게된 내용
1. ablation study
- 모델이나 알고리즘의 feature들을 제거하면서 어떤 성능을 줄지 연구하는 것
2. object detection vs sementic segmentation vs instance segmentation
- object detection
- 바운딩 박스나 라벨링으로 다중객체 인식
- sementic segmentation
- 픽셀별로 어떤 카테고리에 속하는지 구분
- 개별로 분류가 불가능하다
- instance segmentation
- object detection에서 바운딩 박스 대신에 segmentation 출력
3. 데이터셋의 전처리 과정


4. mini-batch SGD
- 딥러닝 모델에서 가장 중요한 것은 loss function을 줄이기 위한 것으로, 대표적인 기법이 Gradient Descent다. 기본 개념은 함수의 기울기를 구하여, 기울기가 낮은쪽으로 계속 이동시켜서 극값에 이를 때까지 반복시키는 것이다.
- learning_rate를 가지고 학습 파라미터를 업데이트하는 과정을 여러 iteration을 통해 최적의 파라미터 도출한다.
- 따라서 GD는 엄청난 계산량이 필요하기 때문에, 이를 개선하기 위해 한 iteration에 하나의 sample만 사용하는 Stochastic Gradient Descent가 등장하였다.
- 하지만 iteration을 계산하는 속도는 빨라졌지만, gradient 추정값이 noise해지는 단점이 있다.
- 이러한 문제들을 보완하는 것이 mini-batch SGD로, 매 iteration마다 적당한 크기의 batch를 잡아서 학습시킨다.
5. weight decay
- 데이터가 단순하고 모델이 복잡하면, 학습을 하면서 굉장히 작은값이었던 weight값이 점점 증가하게 되면서 overfitting이 발생하게 된다.
- weight값이 커질수록 학습 데이터에 영향을 많이 받게 되기 때문에 학습 데이터에 따라 모델이 맞춰진다. 따라서 하이퍼 파라미터의 개수를 최소화하고 알고리즘을 개선함으로써 학습 데이터를 작게 유지하면서 하이퍼 파라미터의 개수의 감소로 모델의 복잡성을 감소시켰지만, 이는 대량의 데이터에서는 underfitting이 발생할 수 있기 때문에 좋지 않다.
- 이러한 배경에서 weight decay 기법이 등장하였다. weight값이 증가하는 것을 제한함으로써, 모델의 복잡도를 감소(decay, 부식)시킴으로써 overfitting을 방지할 수 있다.
6. weight & bias
- 딥러닝 모델의 대표적인 매개변수이다.
- 예를 들어, 중고차의 가격을 예측해보자.
- [가정 1] 중고차는 최신일수록 비쌀 것이다.
- [가정 2] 중고차는 많이 달릴수록 쌀 것이다.
- 위의 가정을 바탕으로 중고차의 가격(price) = w1 x 연식(year) + w2 x 주행거리(miles) 라는 식을 도출할 수 있을 것이다. 이와 같이 결과값에 영향을 주는 입력 파라미터에 중요도를 주는 것이 weight이다.
- bias는 단순히 입력과 가중치의 곱에 추가되는 상수값이다. 활성화 함수(가중치가 높은 쪽으로 활성화)의 기능을 이끌어주는 역할을 한다.
- 만약 bias가 없다면, 신경망은 단순히 입력과 가중치에 대해 행렬 곱셈을 수행하여 데이터셋이 overfitting이 될 수 있다.
7. reduced precision
- Neural Network training과 inference 성능은 메모리 대역폭에 크게 좌우된다. 메모리 시스템은 일반적으로 훈련 데이터와 함께 신경망 매개변수(weight, bias)를 유지하는 작업을 수행하기 때문이다.
- 신경망의 대역폭 수요를 줄이고, 전력 효율을 높일 수 있는 방법이 reduced precision computation이다.
- precision이란, 부동소수점을 표현한 수가 실수를 정확히 표현하는가이다.
- 부동소수점 표현에 유효숫자 개념이 들어있는데, 이 유효숫자가 늘어나면 정확도가 높아지지만 계산량이 많아지면서 속도가 저하된다.
- 반대로 유효숫자가 줄어들면 정확도가 낮아지지만 계산량이 적어지면서 속도가 향상된다.
- 이때 precision을 줄이면 최소 유효 자릿수 계산을 피함으로써 절약되는 전력이 꽤 쏠쏠하다.
- 즉, 네트워크 파라미터 정확도를 감소시킬 때 손실된 분류 정확도를 다시 얻을 수 있도록 네트워크를 다시 훈련시킬 수 있다.
8. annealing strategy
9. knowledge distillation
- 딥러닝 모델은 보편적으로 넓고 깊어서 파라미터 수가 많고 연산량이 많으면 feature extraction이 더 잘되고, 그에 따라서 모델의 목적인 classification이나 object detection 등의 성능이 좋아진다.
- 그러나 작은 모델로 더 큰 모델만큼의 성능을 얻을 수 있다면 computing resource(CPU, GPU), energy, memory 측면에서 더 효율적이다.
- 즉, knowledge distillation은 작은 네트워크로도 큰 네트워크와 비슷한 성능을 낼 수 있도록, 학습과정에서 큰 네트워크의 지식을 작은 네트워크에 전달하여 작은 네트워크의 성능을 높이겠다는 목적이다.
- knowledge distillation의 구조에서 미리 학습시킨 teacher network의 출력을 내가 실제로 사용하고자 하는 작은 모델인 student network가 모방하여 학습함으로써, 상대적으로 적은 파라미터를 가지고 있더라도 모델의 성능을 높일 수 있다.
10. mixup training
- 무작위 쌍의 이미지와 관련 레이블을 convexly하게 결합하여 추가 샘플이 생성되는 DNA를 학습하기 위한 방법이다.
- 데이터에 독립적인 이미지를 augumentation하는 기법으로, 두 데이터의 이미지와 라벨을 각각 weighted linear interpolation하여 새로운 샘플을 생성하는 기법이다.
참고자료
On Mixup Training: Improved Calibration and Predictive Uncertainty for Deep Neural Networks