MobileNet
-
MoblieNet은 컴퓨터 성능이 제한되거나 배터리 퍼포먼스가 중요한 곳에서 사용될 목적으로 설계된 CNN 구조이다.
-
Cloud Computing vs Edge Computing
-
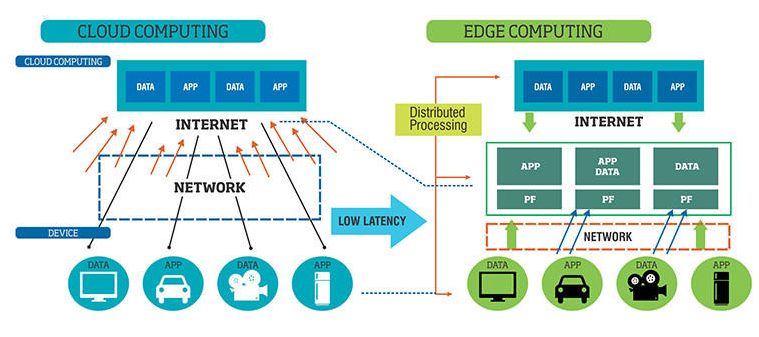
클라우드 컴퓨팅은 여러 디바이스들에서 나온 정보들을 클라우드에서 전부 처리하는 환경이다. 네이버의 NDrive, 구글의 Docs 등이 클라우드 컴퓨팅의 대표적인 예라고 할 수 있다. 클라우드 컴퓨팅이 탄생하면서 여러 기업들에 각광받으며 클라우드 환경으로 전환하였다. 그러나 클라우드 컴퓨팅에도 여러 문제가 있었다. 클라우드 서비스를 이용하는 사람들이 기하급수적으로 늘어나면서 서버 및 데이터 센터에서 처리할 수 있는 데이터의 양을 넘어서기 시작했고, 수집한 데이터를 분석하고 송신하는 과정에서 바랭하는 데이터 지연 현상도 문제가 발생했다. 또한, 컴퓨팅의 통신 과정에서 보안 문제도 발생하며, 데이터 처리 속도, 용량 및 보안 등의 문제를 해결하기 위해 탄생한 것이 엣지 컴퓨팅이다.
-
엣지 컴퓨팅은 클라우드에서 모든 연산을 처리하는 것이 아니라, 모바일 디바이스들이 직접 연산을 하거나, edge들에서 데이터 연산을 하여 cloud에 데이터를 뿌려주는 것이다. 즉, 클라우드 컴퓨팅은 데이터를 처리하는 곳이 데이터 센터에 있는 반면 엣지 컴퓨팅은 스마트폰과 같은 장치에서 데이터를 처리한다.
-
엣지 컴퓨팅의 장점 3가지 1) 데이터 부하 감소
: 클라우드 컴퓨팅에서는 처리해야 할 데이터 양이 많을수록 시스템에 부하가 생기는 반면, 엣지 컴퓨팅은 해당 기기에서 발생되는 데이터만 처리하기 때문에 부하를 줄일 수 있다.2) 보안
: 클라우드 컴퓨팅은 중앙 서버 아키텍처로 데이터 전송부터 보안을 강화해야 하는 반면, 엣지 컴퓨팅은 데이터 수집과 처리를 자체적으로 처리하기 때문에 클라우드 컴퓨팅에 비해 상대적으로 보안이 좋다고 할 수 있다.3) 장애대응
: 클라우드 컴퓨팅을 사용했을 때 서버가 마비되면 치명적인 타격을 입지만, 엣지 컴퓨팅을 사용하면 자체적으로 컴퓨팅을 수행하기 때문에 효과적으로 장애를 대응할 수 있다. -
이러한 엣지 컴퓨팅 환경은 MobileNet과 같이 비대한 크기의 네트워크보다는 빠른 성능이 필요한 곳에서 사용한다.
-
- Techniques for Small Deep Neural Networks
-
DNN에서 작은 네트워크를 만들기 위한 기법으로 다음과 같이 있다.
1) Remove fully-connected layers
2) Kernel reduction(3x3 -> 1x1)
3) Channel reduction
4) Evenly spaced downsampling
- 초반에 downsampling을 많이 하면 accuracy가 떨어지지만, 파라미터의 수가 적어짐.
- 후반에 downsampling을 많이 하면 accuracy가 좋아지지만, 파라미터의 수가 많아짐.5) Depthwise separable convolutions
- depthwise convolution은 채널 숫자는 줄어들지 않고, 한 채널에서의 크기만 줄어든다.
- pointwise convolution은 채널 숫자가 하나로 줄어든다.6) Shuffle operations
7) Distillation & Compression -
MobileNet은 위의 7가지 중 3) channel reduction, 5) depth separable convolutions 7) distillation & compression 기법을 사용한다.
-
- Depthwise Seperable Convolutions
-
채널의 수를 증가시키면서 구성된 convolution-pooling의 구조는 이해도 쉽고 구현하기도 쉽지만, 모바일 환경에서 구동시키기엔 convolution 구조가 무겁다. 따라서 이를 해결하고자 새로운 convolution 연산인 depthwise separable convolution이 등장한 것이다.
-
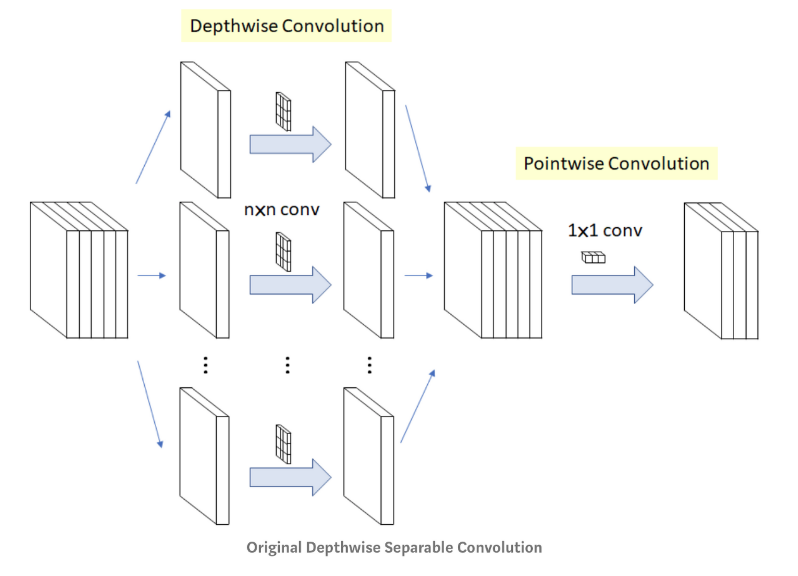
Xception 모델에서 나온 개념으로, convolution 연산을 각 채널별로 시행하고 그 결과에 1x1 convolution 연산을 취하는 것이다. 기존의 convolution이 모든 채널과 지역 정보를 고려해서 하나의 feature map을 만들었다면, depthwise convolution은 각 채널별로 feature map을 하나씩 만들고, 그 다음 1x1 convolution 연산을 수행하여 출력되는 feature map의 수를 조정한다. 이때의 1x1 convolution 연산을 pointwise convolution이라고 한다.
-
위와 같은 구조를 하면 어떤 장점이 있을까? 커널이 3개라 가정할 때, 1) 기존의 convolution의 경우, (3x3)x3(R, G, B)의 커널이 3개이므로 파라미터의 수는 3x3x3x3 = 81개가 된다.
2) depthwise separable convolution의 경우, (3x3)x1의 커널이 3개(depthwise)(채널 별로 분리, R, G, B), (1x1)x3(출력의 채널을 3으로 설정)의 커널이 3개(pointwise)이므로 파라미터의 수는 3x3x1x3 + 1x1x3x3 = 36개가 된다. -
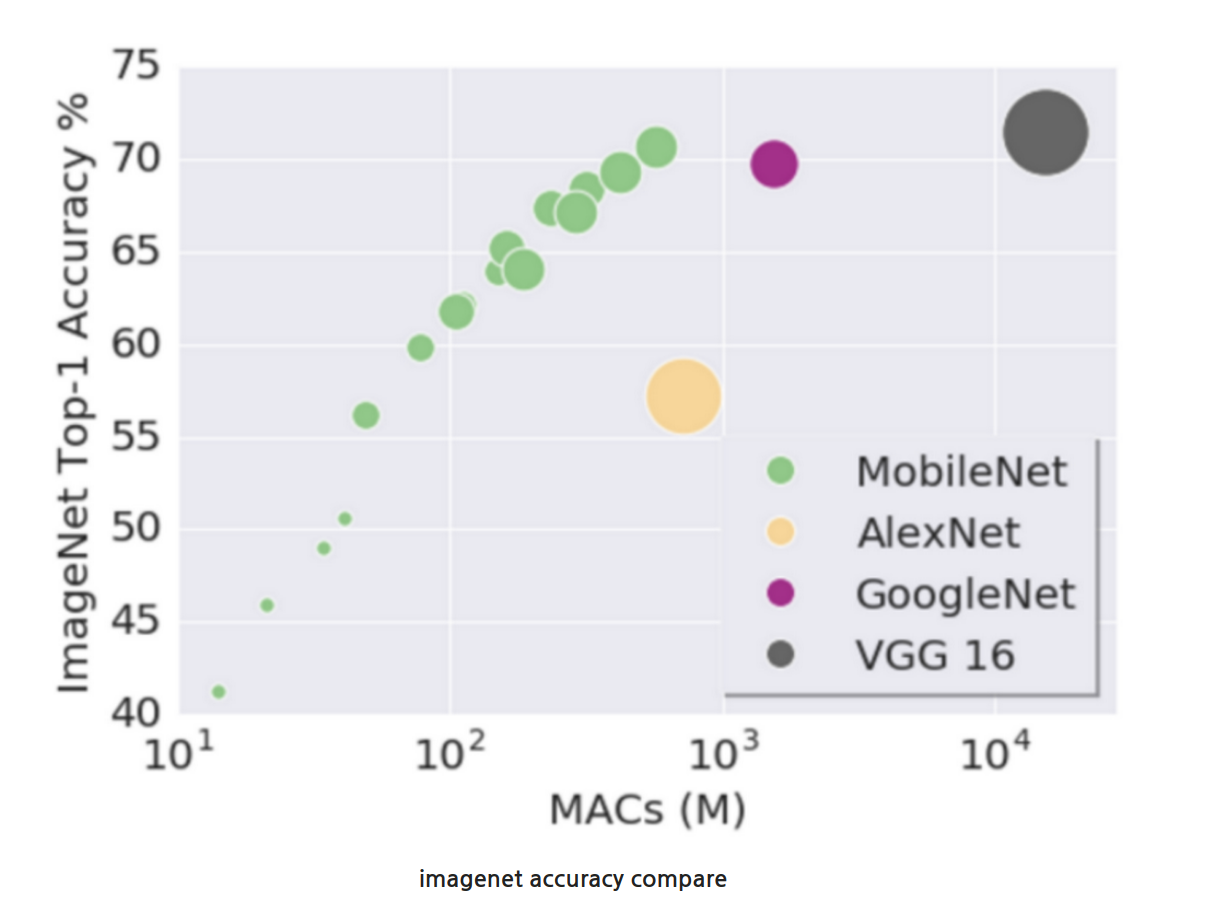
depthwise separable convolution은 다음 그림과 같은 효율이 있다.
-
구조
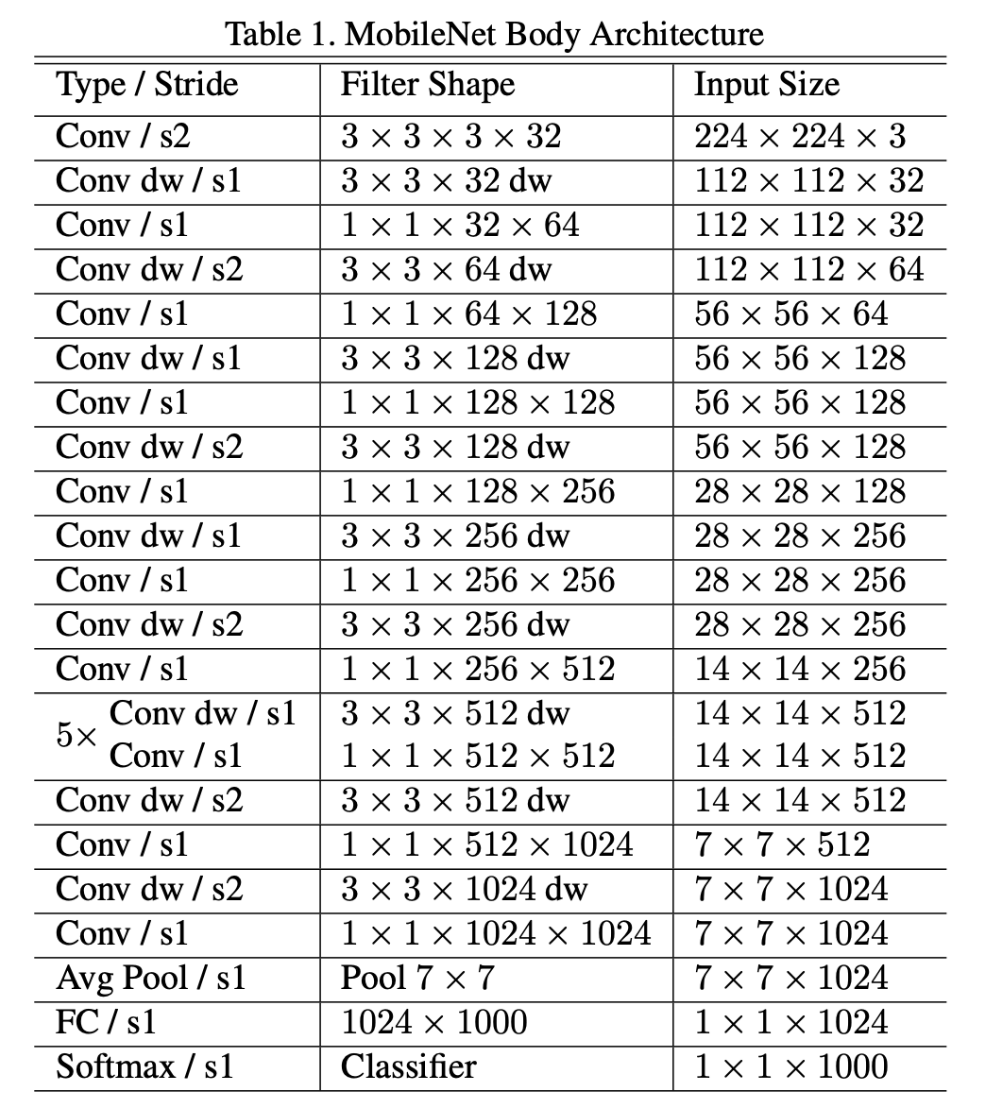
- MobileNet의 구조는 VGGNet의 구조와 비슷하지만, 기존의 convolution을 depthwise separable convolution으로 대체하고, pooling 대신에 stride를 2로 설정하여 사이즈를 축소하고 있다.
참고자료
[논문리뷰] MobileNet V1 설명, pytorch 코드(depthwise separable convolution)