ResNext
-
vision recognition에 대한 연구는 “feature engineering”에서 “network engineering”으로 변화하는 추세이다. 따라서 feature가 수작업으로 만들어지는 것이 아닌, model의 architecture를 만드는 것으로 옮겨지고 있다.
-
하지만 architecture를 디자인하는 것은, 특히나 layer의 층이 깊어질수록 hyper parameter의 증가로 그 난이도가 어려워지고 있다. 같은 모양의 여러 블록을 쌓는 VGGNet처럼, ResNet도 VGGNet과 같은 방식으로 계승했고, 이 간단한 rule은 hyper parameter의 선택을 보다 간단하게 만들어주었다. 또한, VGGNet과 달리 Inception module은 낮은 연산량으로도 높은 정확도를 이끌어낼 수 있다고 증명했다. Inception module은 계속 발전하고 있지만, 메인 아이디어는 split-transform-merge 형태의 전략이다.
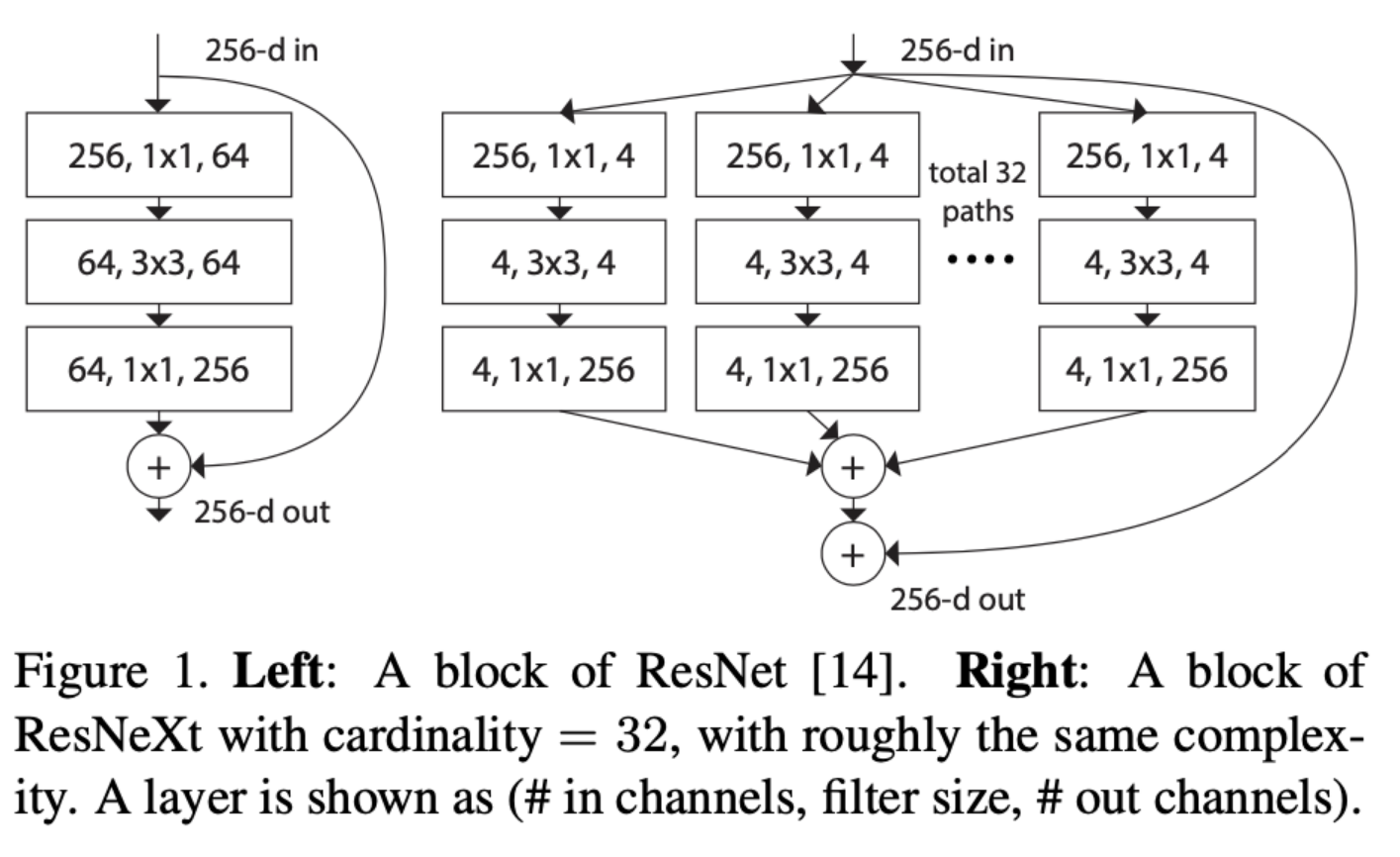
- ResNext는 하나의 입력을 group convolution을 통해 여러개로 나누고, 1x1 convolution으로 입력을 transform하고, concat을 통해 merge를 진행한다. 또한, 기존의 ResNet보다 연산량은 줄이면서 더 높은 성능을 보여주었다.
구조
- 위의 그림은 ResNet과 ResNext의 기본 구성으로, ResNext에서 나오는 파라미터 C는 Cardinarity로, 새로운 차원의 개념을 도입한다. cardinality는 집합의 크기 또는 집합의 원소의 개수를 의미하는데, CNN에서는 하나의 block 안의 transformation 개수 혹은 path, brach의 개수 혹은 group convolution의 수로 볼 수 있다. 그림에서 64개의 filter의 개수를 32개의 path로 쪼개서 각각 path마다 4개씩 filter를 사용하는 것을 보여주고 있는데, 이는 AlexNet에서 사용했던 grouped convolution과 유사한 방식이다.
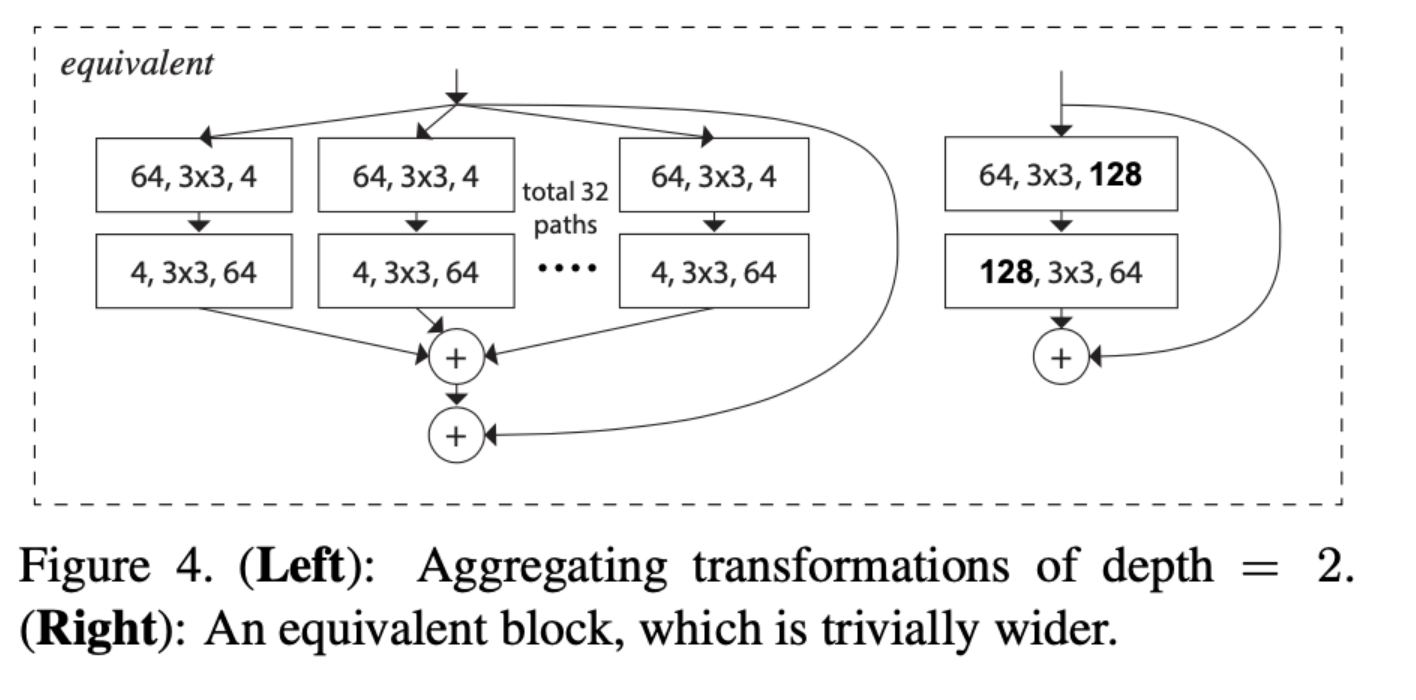
- 이전의 ResNet에서, ResNet50 이하의 깊이를 갖는 구조에서는 basic block, 즉 블록을 하나 쌓을 때, convolution을 2번 진행하였다. 하지만 ResNext에서는 2개의 블록만 쌓게 된다면 group convolution의 의미가 없어져 성능 향상에 의미가 없게 된다. 따라서 ResNext에서는 block의 depth가 3 이상일 때부터 성능이 향상된다고 한다.
실험
-
ImageNet dataset을 사용하며, input image를 224x224 random crop하였다.
-
shortcut connection을 위해서는 identity connection을 사용했다.
-
downsampling은 convolution 3, 4, 5 layer에서 진행하였으며, 각 layer의 첫 번째 블록에서 stride=2로 설정하였다.
-
SGD optimizer, mini-batch 256, 8 GPU를 사용했으며, weight decay=0.0001, momentum=0.9로 설정하였다.
-
learning rate는 0.1로 시작하여 학습을 진행하면서 3번에 걸쳐 1/10로 감소시켰다.
-
weight initialization을 사용하였고, 모든 convolution 이후에는 BN을 수행하였고, 그 이후에는 ReLU로 활성화 시켰다.
특징
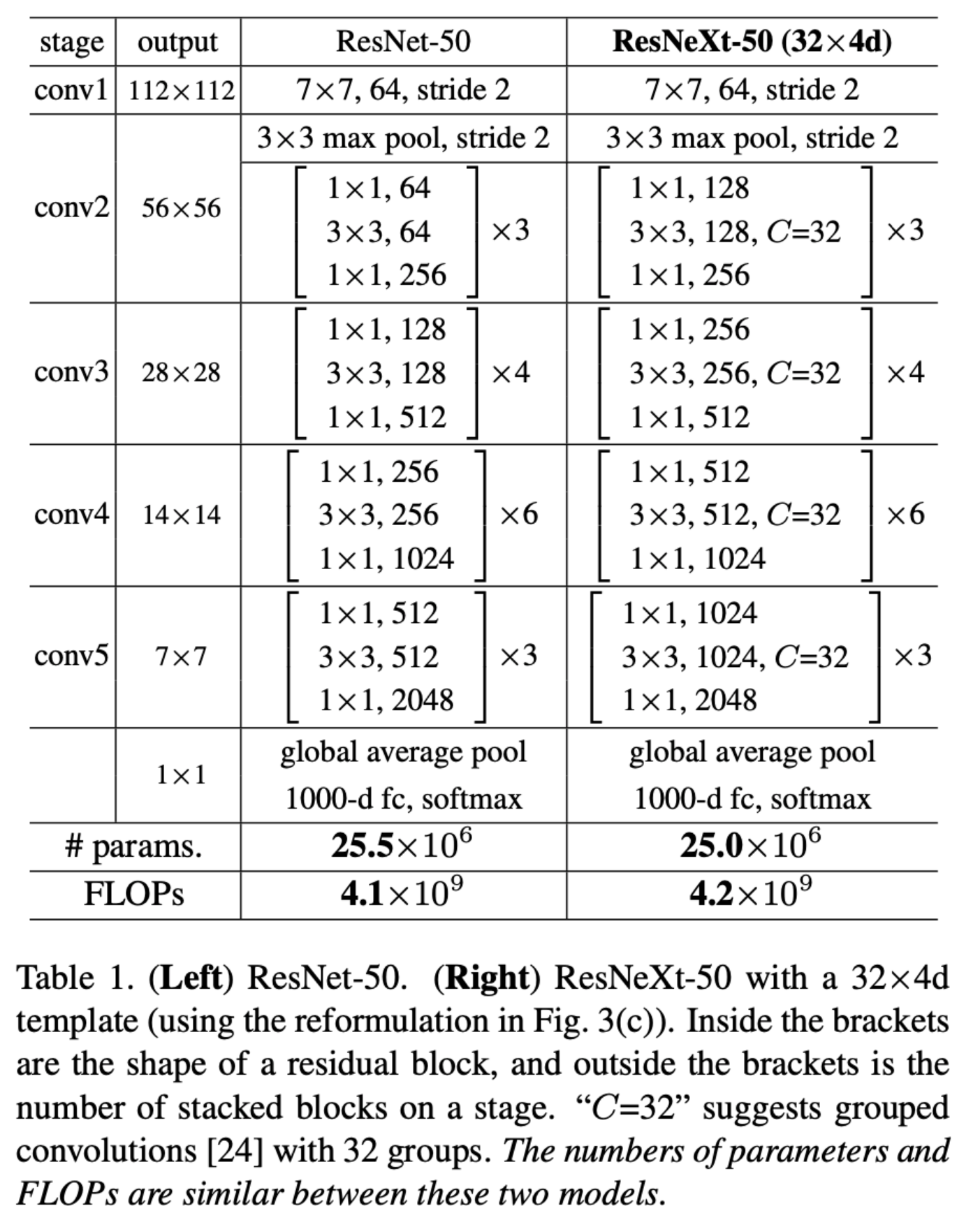
- ResNext의 큰 특징이라고 하면 group convolution이다. 이때 group의 수를 cardinality라고 하는데, group의 수를 늘릴수록 더 낮은 연산량을 가질 수 있다. 따라서 같은 연산량을 갖는 네트워크라고 하면, group을 늘리면 더 깊은 채널을 가질 수 있다.

- 위의 표는 파라미터를 일정 수준으로 유지하면서 cardinality와 block width를 변경해주면서 비교한 표이다. group의 수를 늘리면 더 많은 채널을 이용할 수 있다.
참고자료
ResNeXt:Aggregated Residual Transformations for Deep Neural Networks