Residual Attention Network
- ResNet에 Attention mechanism을 convolution network에 접목시킨 구조이다.
- Attention이란?
-
RNN은 출력이 바로 이전 입력까지만 고려해서 정확도가 떨어진다. 전체 입력 문장을 고려하지 않고 다음 문장을 생성하기 때문이다. 그래서 seq-to-seq 모델이 등장하게 되었다. RNN은 시퀀스에서 작동하고 후속 단계의 입력으로 자신의 출력을 사용하는 네트워크이다. seq-to-seq는 2개의 RNN으로 구성된 모델이다. Encoder와 Decoder로 구성되며, Encoder는 입력 시퀀스를 읽고 단일 벡터를 출력하고 이 단일 벡터는 Context Vector라고도 불린다. Decoder는 Context Vector를 읽어 출력 시퀀스를 생성한다.
-
seq-to-seq 모델은 시퀀스 길이와 순서를 자유롭게 하여 두 언어간의 번역과 같은 task에 이상적이다. 하지만, LSTM의 한계와 마찬가지로 입력 문장이 매우 길면 효율적으로 학습하지 못한다.
-
seq-to-seq 모델의 2가지 문제가 있는데, 1) 하나의 고정된 크기의 벡터에 모든 정보를 압축하려고 하니까 정보 손실이 발생한다. 2) Vanishing Gradient의 문제가 존재한다. 의 문제를 가지고 있다.
-
이러한 문제와 한계를 보정하기 위해 중요한 단어에 집중(attention)하여 decoder에 바로 전달하는 Attention 기법이 등장하였다.
-
Attention의 기본 아이디어는 Decoder에서 출력 단어를 예측하는 매 시점마다, Encoder에서 전체 입력 문장을 다시 한 번 참고한다는 점이다. 단, 전체 입력 문장을 전부 다 동일한 비율로 참고하는 것이 아니라, 해당 시점에서 예측해야 할 단어와 연관이 있는 입력 단어 부분을 좀 더 집중해서 보게 된다.
-
이미지에서의 attention은 image classification과 detection 등에 적용되면서, 강인한 feature에 집중하여 추출하도록 할 때 사용된다.
-
- Attention의 아이디어를 computer vision 문제에 접목시켰다. 다음 그림과 같이 Attention을 적용하기 전에는 feature map이 분류하고자 하는 물체의 영역에 집중하지 못하는 경향이 있는데, Attention을 적용하면 feature map을 시각화했을 때, 물체의 영역에 잘 집중하고 있는 것을 확인할 수 있다.

특징
-
Attention module의 수를 증가시키면, 성능이 일정하게 늘어난다. 또한 각각의 module은 서로 다른 형식의 attention을 감지하도록 학습된다.
-
기존의 DNN 구조에 바로 적용하여 end-to-end로 학습이 가능하다.
- 여러 Attention module을 쌓는 대신, 하나의 네트워크로 마스크를 생성하는 방법도 있지만 몇 가지 단점이 있다.
-
첫 번째는 복잡하거나 많은 모양 변화를 가지는 경우에는 서로 다른 방식의 attention을 가지도록 모델링이 되어야만 한다. 하지만 그렇게 되려면 각 layer의 feature가 서로 다른 attention 마스크를 가지도록 해야 하는데, 하나의 마스크로는 불가능하다.
-
두 번째는 하나의 module은 하나의 feature에만 영향을 주기 때문에, 잘못 적용하면 다음에 수정하기란 매우 힘들다.
-
- 이러한 단점을 해결하기 위해 각 Trunk Branch에 붙은 Soft Mask Branch는 그 feature에 맞는 specialized된 마스크를 제공한다.
구조
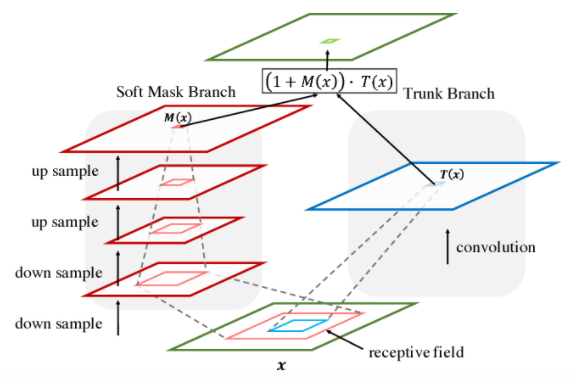
-
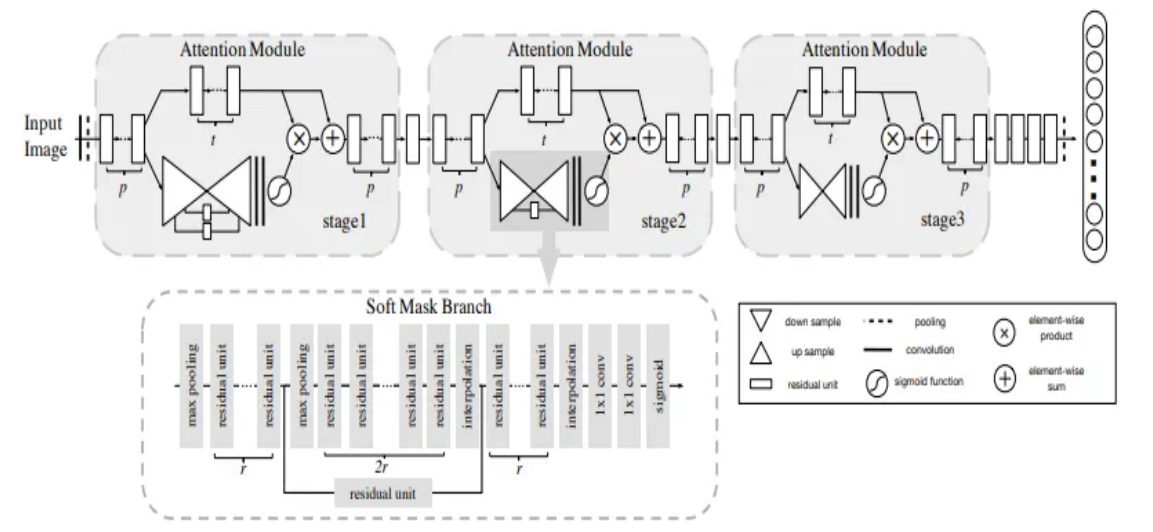
Residual Attention Network는 여러 Attention Module을 쌓아서 만들었다. 각 Attention Module은 Soft Mask Branch와 Trunk Branch로 이루어져 있다.
- Trunk Branch
- feature를 만들어내는 브랜치로, 일반적인 convolution 연산이 수행된다.
- Soft Mask Branch
-
Attention mechanism에 따르면, Mask Branch는 fast feed-forward sweep과 top-down feedback step을 가지고 있다. 첫 번째 것은 전체 이미지의 글로벌 정보를 수집하고, 다음 단계로 글로벌 이미지 정보를 원래 feature map에 통합하게 된다. convolution network에서는 이를 bottom-up top-down의 fully convolutional 구조로 풀어지게 된다.
-
입력된 데이터를 약간의 residual unit을 통과시킨 다음 max pooling을 몇 번 적용하여 receptive field를 증가시킨다. 가장 낮은 해상도까지 다다르면 input feature의 글로벌 정보는 확장되어 각 위치로 들어간다. 다시 residual unit을 몇 번 통과시킨 뒤, max pooling과 같은 수로 linear interpolation으로 출력을 upsampling하면, 원래의 input feature와 같은 크기로 확장할 수 있다.
-
마지막으로 1x1 convolution 연산을 적용한 뒤 sigmoid 활성화를 하여, 출력값을 0에서 1로 조절한다. 여기에 bottom-up과 top-down 사이에 skip connection을 추가하여 스케일간 정보를 얻도록 하였다.
-
- Attention Residual Learning
-
단순히 attention module을 쌓는 것만으로는 성능이 올라가지 않는데, 0에서 1사이의 값을 가진 마스크가 계속 적용되면서 feature들이 점점 약해지기도 했고, 마스크가 Trunk Branch의 residual unit의 identical mapping 성질을 깨버리기도 했기 때문이다.
-
따라서 마스크가 identical mapping을 유지할 수 있도록 하기 위해 attention module의 출력값 H(x)를 수정하였다. 식 \(H_{i,c}(x) = (1 + M_{i,c}(x)) * F_{i, c}(x)\) 에서 \(M(X)\)는 0에서 1사이의 범위를 가지기 때문에 만약 값이 0인 경우, 원래의 특징 \(F(x)\)을 내보내도록 될 것이다. 이것을 attention residual learning이라고 한다. 즉, 마스크의 역할은 feature 중 더 좋은 feature를 강조하고, noise feature를 약하게 하는 역할을 할 수 있게 된다.
-
- Attention을 주는 방식이 Spatial Attention과 Channel Attention이 있다.
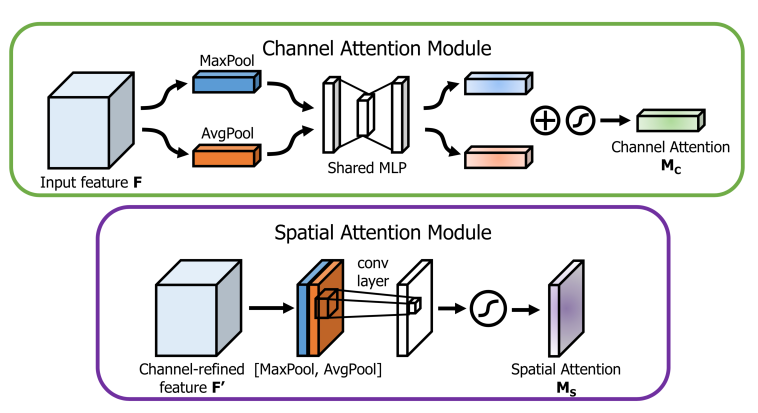
1) Channel Attention
- Feature map의 “what”에 집중된다.
- 일반적으로 공간의 차원을 압축하여 정보를 집계하는 average pooling을 사용하며, 여기에 채널에 대한 더 세밀한 관심을 inference하기 위해 max pooling을 동시에 사용한다. 이처럼 독립적으로 사용하는 것보다 모두 이용하는 것이 네트워크의 표현력을 크게 향상시키는 것을 확인할 수 있다.
2) Spatial Attention
- feature의 공간적 관계를 이용하는 것으로, feature map의 “where”에 집중한다.
- channel attention을 보완하는 정보적인 부분으로, channel attention처럼 average/max pooling을 적용하고, 이를 연계하여 효율적인 feature를 생성한다.
- convolution layer를 적용하여 생성하며, 2개의 pooling을 사용하여 feature map의 채널 정보를 집계한 후 강조하거나 억제할 위치를 인코딩한다.