Object Detection Tutorial by HOYA012’S RESEARCH BLOG
1. Object Detection이란?
-
Image Classification은 이미지를 넣으면 그 이미지에 해당하는 class를 분류해내는 방법
-
Object Detection은 Image Classification에 사물의 위치를 Bounding Box로 예측하는 Regression이 추가된 방법
2. 대표적인 Object Detection 기법인 R-CNN
-
Object Detetion에 CNN을 적용한 첫 논문
-
selective search를 통해 region proposal을 수행, proposal된 영역들을 CNN의 고정 사이즈를 가지는 입력으로 변환시키고, 각 영역마다 classification을 수행
-
proposal된 region에서 실제 object의 위치와 가까워지도록 보정해주는 regression도 수행
-
초기에는 detection의 성능을 향상시키는데 초점을 두는 연구를 진행, 최근에는 연산을 가속하는 연구들과 효율적으로 학습을 시키는 방법으로 연구가 진행
3. Object Detection의 연구 방향 2가지
-
Region Proposal과 Detection의 과정이 순차적으로 진행되는지(2-stage object detector), 한 번에 진행되는지(1-stage object detector)
- R-CNN 계열의 연구들(R-CNN, Fast R-CNN, Faster R-CNN)이 2-stage object detector
- 비교적 느리지만 정확하다
- SSD, YOLO가 1-stage object detector
- 빠르지만 부정확하다
4. Object Detection의 성능
- 정확도 계산은 주로 정답(Ground Truth)과 모델이 예측한 결과(Prediction) 간의 비교를 통해 이루어진다.
- Image Classification의 경우에는 GT가 이미지의 class
- Object Detection은 이미지의 각 object에 해당하는 Bounding Box와 Box 안의 class
-
정확도가 높다는 것은 모델이 GT와 유사한 Bounding Box를 예측하면서 동시에 Box 안의 ojbect의 class를 잘 예측하는 것을 의미, 즉 class도 정확하게 예측하면서 동시에 object의 영역까지 잘 예측
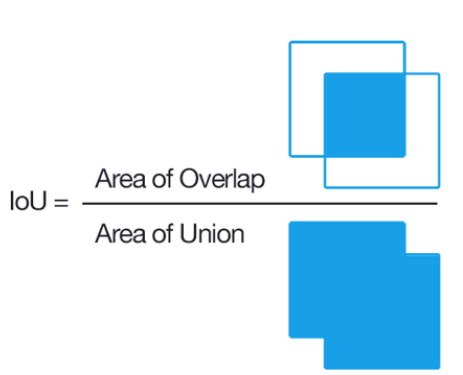
- IoU(Intersection Over Union)
- Object Detection에서 Bounding Box를 얼마나 잘 예측했는지 IoU라는 지표를 통해 측정
-
IoU = Area of Overlap / Area of Union
- 교집합이 없는 경우 0, 예측 결과가 100%이면 1
- 일반적으로 0.5를 넘으면 정답
-
Pascal VOC는 0.5로 threshold로 설정
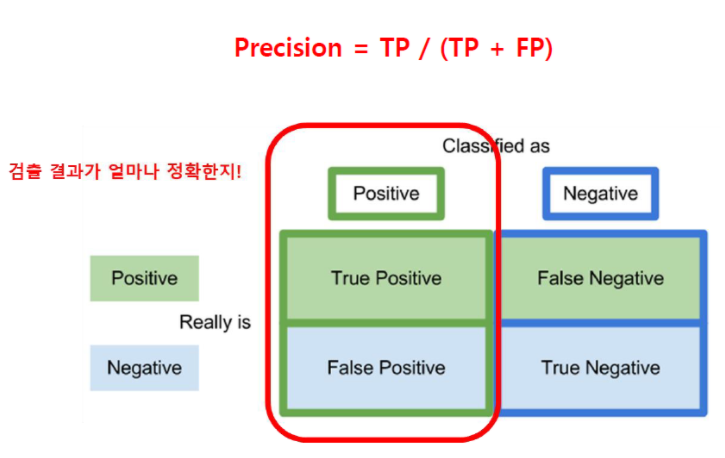
- Precision = TP / (TP + FP)
- 주로 예측된 결과가 얼마나 정확한지를 나타는데 사용
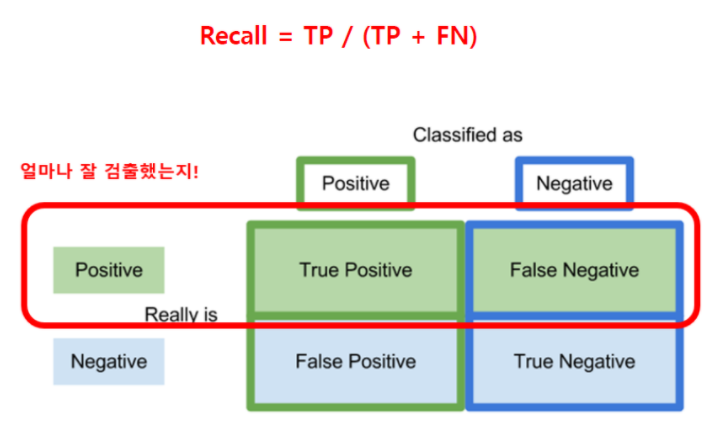
- Recall = TP / (TP + FN)
- 입력으로 Positive를 주었을 때 얼마나 잘 Positive를 예측하는지
- 정답을 많이 맞출수록
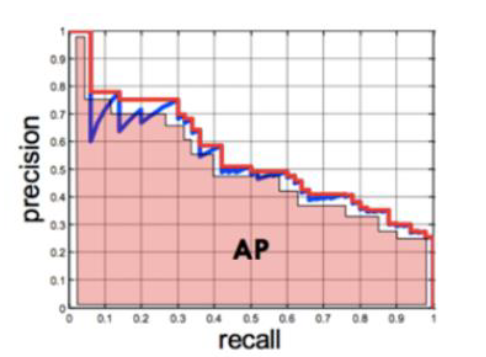
- AP(Average Precision)
- Recall을 0부터 0.1단위로 증가시켜서 1까지 증가시킬 때 필연적으로 Precision이 감소하는데, 각 단위마다 Precision 값을 계산하여 평균을 내어 계산한다.
- mAP(mean Average Precision)
- 전체 class에 대해 AP를 계산하여 평균을 낸 값이 mAP
- FPS(Frame Per Second)
- 속도를 나타낼 때 보통 초당 몇 장의 이미지가 처리 가능한지
5. Domain Randomization 기법
-
Object Detection의 성능 중 정확도를 개선하는 방법
-
직접 데이터셋을 구축하는 경우, 데이터를 취득하고 labeling을 하는데 많은 시간과 비용이 드는 문제가 있다. 이를 해결하기 위해 실제 이미지와 비슷하게 생긴 이미지를 생성하는 simulator 연구도 등장하였다. 하지만 이러한 방법 역시 simulator를 제작하는 시간과 비용, 인력 등이 필요한 한계가 있다.
-
따라서 domain randomization이라는 기법을 object detection 문제에 적용하여, 저비용으로 대량의 이미지를 합성하여 데이터셋을 만들고, 정확도를 향상시키는 방법을 제안한다.
-
현재 진행 중인 무인 가판대에 domain radomization 기법으로 가상의 데이터를 합성하여 데이터를 늘리는 방법도 괜찮을 것 같다.
6. multi-scale testing 방식
-
Object Detection의 성능 중 정확도(mAP 성능)를 개선하는 방법
-
하나의 이미지에 대해서 여러 scale에서 test를 하는 방법
-
대표적으로 SSD는 여러 scale의 feature map에 대해 적용, YOLO는 학습 데이터의 해상도를 320x320부터 608x608까지 다양한 scale로 resize를 하여 학습을 시켰다. 이러한 방식들은 학습 단계에 feature map 혹은 input image 자체에 multi scale을 적용한다.
-
multi-scale testing 방식은 하나의 이미지에 대해 여러 번 test를 해야 하기 때문에 전체적인 task time은 늘어나지만, 정확도를 많이 높일 수 있다.
7. 읽어봐야할 논문
2014
2015
- Fast R-CNN Fast R-CNN
- Faster R-CNN Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks
2016
- YOLO v1 You Only Look Once: Unified, Real-Time Object Detection
- SSD SSD: Single Shot MultiBox Detector
- R-FCN R-FCN: Object Detection via Region-based Fully Convolutional Networks
2017
- FPN Feature Pyramid Networks for Object Detection
- YOLO v2 YOLO9000: Better, Faster, Stronger
- RetinaNet Focal Loss for Dense Object Detection
- Mask R-CNN Mask R-CNN
2018
- YOLO v3 YOLOv3: An Incremental Improvement
- RefineDet Single-Shot Refinement Neural Network for Object Detection
2019
- Generative Modeling for Small-Data Object Detection
- ThunderNet ThunderNet: Towards Real-Time Generic Object Detection on Mobile Devices
- DetNAS DetNAS: Backbone Search for Object Detection
2020
- YOLOv4 YOLOv4: Optimal Speed and Accuracy of Object Detection
- Rethinking Classification and Localization for Object Detection
- EfficientDet EfficientDet: Scalable and Efficient Object Detection
- NETNet NETNet: Neighbor Erasing and Transferring Network for Better Single Shot Object Detection
- Dynamic R-CNN Dynamic R-CNN: Towards High Quality Object Detection via Dynamic Training
- On the Importance of Data Augmentation for Object Detection
- Quantum-soft QUBO Suppression for Accurate Object Detection