R-CNN
1. 구조
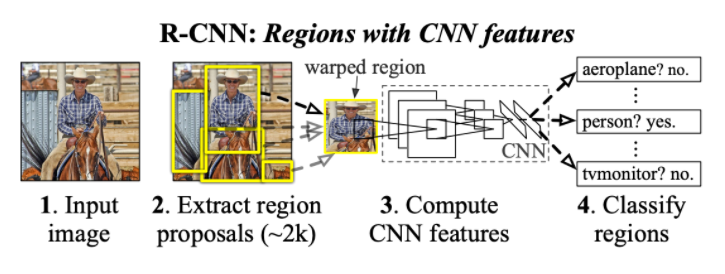
2. 동작 방식
- input image에 bounding box를 그리고, selective search 기법을 통해 RoI(Region Of Interest)를 약 2,000개 정도 추출한다.
- 추출된 RoI 조각들을 동일한 크기로 만들어서, 각각을 CNN(pretrained된 AlexNet)의 끝 단을 object detection class로 fine tuning시켜서 훈련을 한다.
- 훈련 결과 나온 feature들을 SVM에서 classification, bounding regression으로 back propagation 업데이트를 해준다.
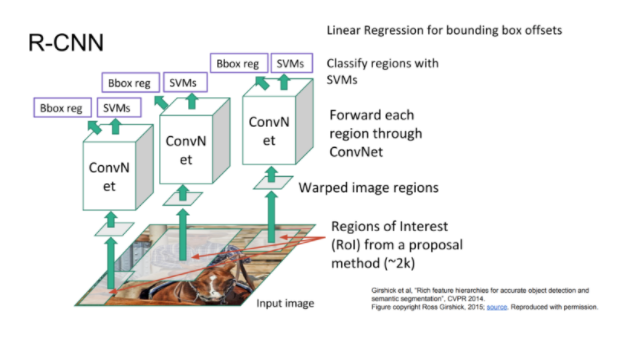
-
Selective Search

- Region Proposal
- 주어진 이미지에서 물체가 있을법한 위치를 찾는 것이다.
- selective search라는 알고리즘을 적용하여 2,000개의 물체가 있을만한 박스를 찾는다.
- selective search는 주변 픽셀간의 유사도를 기준으로 merge를 통해 segmentation을 만들고, 이를 기준으로 물체가 있을만한 박스를 추론한다.
- Feature Extraction
- ImageNet 데이터로 미리 학습된 CNN 모델(AlexNet)을 가져와 fine tune하는 방식을 취했다.
- fine tune시에는 실제 object detection을 적용할 데이터셋에서 ground truth에 해당하는 이미지들을 가져와 학습시킨다.
- classification 마지막 레이어를 object detection의 클래스 수 N과 아무 물체도 없는 배경까지 포함한 N+1로 맞춰준다.
- 이후 selective search 결과로 뽑힌 이미지들로부터 feature vector를 추출한다.
- Classification
- CNN을 통해 추출한 벡터를 가지고 각각의 클래스별로 SVM classifier를 학습시킨다.
- SVM을 사용하는 이유는, 단지 CNN classifier를 썼을 때보다 mAP 성능이 4% 더 낮아졌기 때문이다.
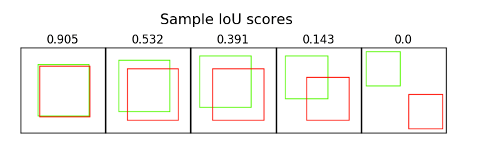
- Non-Maximum Suppression
- OpenCV에서 배웠던 non-maximum suppression으로, 여러 개의 bounding box 중에서 가장 스코어가 높은 박스만 남기고 나머지는 제거한다.
- 기준을 IoU(Intersection over Union) 개념을 적용한다. 두 박스가 일치할 수록 1에 가까운 값이 나온다.
- Bounding Box Regression
- 지금까지 물체가 있을만한 위치를 추론하고, 해당 물체의 종류를 판별할 수 있는 classification 모델을 학습시켰다. 하지만 selective search를 통해서 찾은 박스가 과연 정확한거라고 보장할 수 있을까?
- selective search가 찾은 bounding box의 위치를 교정하기 위해 bounding box regression을 도입한다.
- selective search를 통해 추출된 bounding box에는 다음과 같은 정보들이 포함된다.
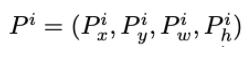
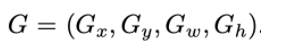
- 하나의 박스에는 x, y좌표와 width, height의 값이 담기고, Ground Truth(정답)은 G로 표현한다.
- 우리는 최대한 정답에 가깝게 만들어줘야 하기 떄문에 다음과 같은 수식을 얻을 수 있다.
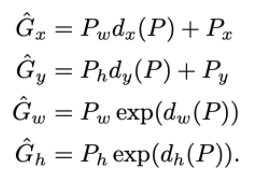
- G에 가깝게 하도록 d의 값을 찾는 것으로 다음과 같은 함수로 가중치를 부여한다.
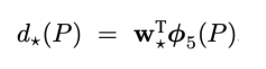
3. R-CNN의 특징
- multi staged training을 해야 한다(fine tune, svm classifier, bounding box regression).
- 2,000개의 영역을 모두 CNN으로 학습하기 때문에 속도가 느리다.