Fast R-CNN
1. 구조
- 이전의 R-CNN이 여러 번 CNN inference하는 방식으로 인해 속도가 저하되었다면, Fast R-CNN은 CNN 특징 추출부터 classification, bounding box regression까지 모두 하나의 모델에 학습시킨다.
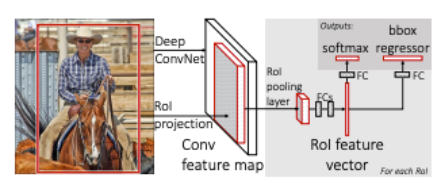
2. 동작 방식
- 전체 이미지를 미리 학습된 CNN을 통과시켜 feature map을 추출한다.
- selective search를 통해서 찾은 각각의 RoI에 대해 RoI Pooling을 진행한다. 그 결과 고정된 크기의 feature vector를 얻는다.
- feature vector는 fully connected layer들을 통과하고, 2개의 브랜치로 나뉜다.
- 첫 번째는 softmax를 통과해서 해당 RoI가 어떤 물체인지 classification한다(SVM 사용 x).
- 두 번째는 bounding box regression을 통해 bounding box의 위치를 업데이트한다.
- RoI Pooling
- 입력된 이미지가 CNN을 통과하여 feature map을 추출한다. 추출된 feature map을 미리 정해놓은 H x W 크기에 맞게끔 grid를 설정한다. 그리고 각각의 칸 별로 가장 큰 값을 추출하는 max pooling을 실시하여 항상 H x W 크기의 feature map이 나오도록 한다.
- 마지막으로 H x W 크기의 feature map을 1차원으로 늘려서 feature vector를 추출한다.
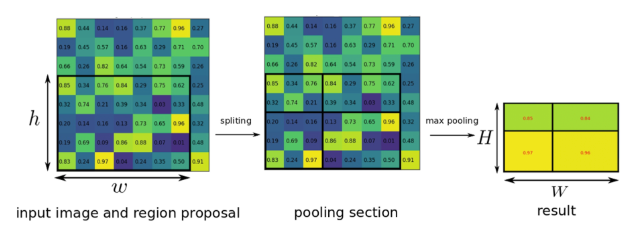
- input image와 feature map의 크기가 다른 경우, 그 비율을 구해서 RoI를 조절한 다음 RoI Pooling을 진행한다.
- Multi Task Loss
- 최종적으로 RoI Pooling을 이용하여 feature vector를 구했다. 이제 이 벡터로 classification과 bounding box regression을 적용하여 각각의 loss를 구하고, 이를 back propagation하여 전체 모델을 학습시킨다.
- 이때, classification loss와 bounding box regression을 적절하게 엮어주는 것을 multi task loss라고 한다.
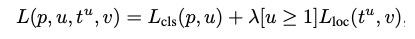
- p는 softmax를 통해서 얻은 N + 1(N개의 object 배경, 아무것도 아닌 배경)개의 확률값이다.
-
u는 해당 RoI의 ground truth의 라벨값이다.
- bounding box regression을 적용하면 위의 식에서 각각 x, y, w, h값을 조정하는 tk를 반환한다. 즉, 이 RoI를 통해 어떤 클래스는 어디 위치로 조절해야하는지에 대한 값이다. loss function에서는 이 값들 가운데 ground truth 라벨에 해당하는 값만 가져오며, 이는 tu에 해당한다.
- v는 ground truth bounding box 조절값에 해당한다.
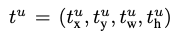
- 다시 전체 로스에서 앞부분 p와 u를 가지고 classification loss를 구한다. 여기서는 log loss를 사용한다.
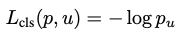
- 전체 로스의 뒷부분은 bounding box regression을 통해 얻은 loss로 다음 수식과 같다.
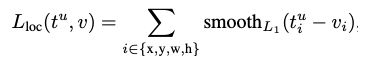
- 위의 수식에서 입력으로는 정답 라벨에 해당하는 BBR 예측값과 ground truth 조절값을 받는다. 그리고 x, y, w, h 각각에 대해서 예측값과 라벨값의 차이를 계산한 다음, smoothL1이라는 함수를 통과시킨 합을 계산한다.
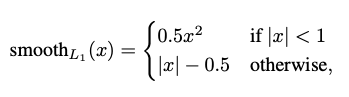
- 예측값과 라벨값의 차이가 1보다 작으면 0.5(x^2)로 L2 distance를 계산해준다. 반면에 1보다 크다면 L1 distance를 계산해준다. 이는 object detection task에 맞춰 loss function을 커스텀하는 것으로 볼 수 있다.
- Backpropagation through RoI Pooling Layer
-
loss function까지 구했고, 네트워크를 학습시키는 일이 남았다. 이전의 SPPNet에서는 feature map을 추출하는 CNN 부분은 놔두고, SPP 이후의 FC들만 fine tune하였다. 하지만 Fast R-CNN에서는 이렇게하면 이미지로부터 feature를 뽑는 가장 중요한 역할을 하는 CNN이 학습될 수 없기 때문에 성능 향상에 제약이 걸린다고 주장한다.
-
과연 네트워크를 어디까지 학습시키는 것이 성능에 가장 좋은지를 검증해보자.
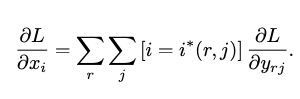
-
xi는 CNN을 통해 추출된 feature map에서 하나의 feature를 의미한다. 전체 loss에 대해서 이 feature 값의 편미분을 구하면 그 값이 곧 xi에 대한 loss값이 되며, back propagation을 수행할 수 있다.
-
feature map에서 RoI를 찾고, RoI Pooling을 적용하기 위해서 H x W 크기의 grid로 나눈다. 이 grid들은 sub-window라고 부르며, 위 수식에서 j란 몇 번째 sub-window인지를 나타내는 인덱스이다. yrj란 RoI Pooling을 통과하여 최종적으로 얻어진 output 값이다.

-
xi가 최종 predicion 값에 영향을 주려면, xi가 속하는 모든 RoI의 sub-window에서 해당 xi가 최대가 되면 된다. i*(r, j)란 RoI와 sub window index j가 주어졌을 때 최대 feature 값의 index를 의미하며, 이는 곧 RoI Pooling을 통과하는 인덱스값을 말한다. 이 RoI Pooling을 통과한 이후 값에 대한 loss는 이미 전체 loss에 대한 yrj의 편미분값으로, 이미 계산되어 있다. 따라서 이를 중첩시키면 xi에 대한 loss를 구할 수 있다.
-
논문의 저자들은 실험을 통해 실제로 CNN까지 fine tuning하는 것이 성능 향상에 도움이 되었다는 결과를 보여준다.

-