DetectorRS: Detecting Objects with Recursive Feature Pyramid and Switchable Atrous Convolution
1. Abstract
- 본 논문에서는 object detection을 위한 backbone 디자인을 탐구할 것이다.
- Macro Level(모델 전체 구조)에서는, FPN(Feature Pyramid Network) 구조에 추가적인 피드백 커넥션을 통합시킨 [RPN(Recursive Feature Pyramid)]를 제안한다.
- Micro Level(모델 세부 구조)에서는, 서로 다른 atrous rates와 switch functions을 사용해 결과를 취합시킨 [Switchable Atrous Convolution]을 제안한다.
- 위의 두 모델을 합친 것이 DetectorRS이며, object detection의 성능을 향상시켰다.
2. Introduction
- two-stage object detection 방식으로 유명한 Faster R-CNN은 object를 감지하기 위해 regional features를 기반으로 object proposal을 출력한다.
-
같은 방식으로, Cascade R-CNN은 multi-stage object detection 방식으로 후속 검출기의 헤드는 더 많은 선택적 예시와 함께 훈련된다.
- Macro Level
-
FPN 위에다가 FPN layer에서부터 bottom-up backbone layer까지의 추가적인 피드백 커넥션들을 통합시킴으로써 구축한 RFP 모델을 제안한다.
-
RFP 모델은 반복적으로 FPN의 성능을 향상시켜주기 위해 강화시킨다.
-
Resembling Deeply Supervised Nets 논문에 따르면, 피드백 커넥션은 디텍터 헤드로부터 직접적으로 gradients를 받아온 features를 낮은 레벨의 bottom-up backbone에 돌려줌으로써, 훈련과 부스트 퍼포먼스의 속도를 높여준다.
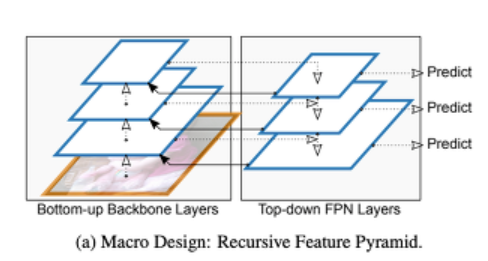
-
- Micro Level
-
다른 atrous 비율을 가진 같은 input feature를 서로 얽히고, switch function을 사용해 결과를 얻는 SAC(Switchable Atrous Convolution)를 제안한다.
-
switch function은 공간적으로 독립적이고, 각 feature map의 location은 SAC의 출력 결과를 제어하기 위한 서로 다른 switches이다.
-
디텍터로서 SAC를 사용하기 위해서, 3x3 convolution layer를 SAC의 bottem-up backbone으로 변환했다. 이렇게 하면 large margin에 의해 디텍터의 퍼포먼스가 향상된다.
-
이전의 방식들은 단일 출력으로서 다른 convolution들의 결과를 통합시킬 수 있는 조건부적인 convolution 방법을 적용했다. 이러한 방식들은 scratch로부터 학습시키는 방식이지만, SAC는 쉽게 미리 훈련된 표준 convolution 네트워크들에 전환할 수 있는 메커니즘을 제공해준다.
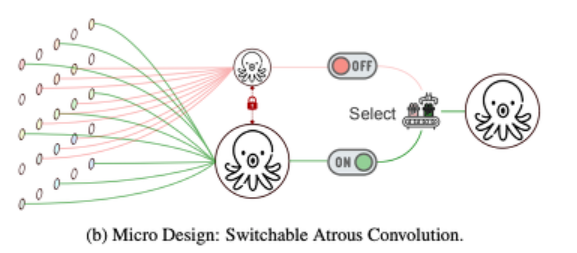
-
3. Related Works
- Object Detection
-
object detection에는 2가지 메인 카테고리가 있다. one-stage methods, multi-stage methods
-
multi-stage 디텍터는 one-stage 디텍터에 비해 더 복잡하지만 유연하고, 정확하다.
-
본 논문에서는 multi-stage 디텍터인 HTC(Hybrid Task Cascade)를 기반으로 사용한다.
-
- Multi-Scale Features
-
본 논문에서 사용되는 RFP는 multi-scale features를 탐색하는데 사용되는 FPN을 기반으로 사용한다.
-
이전까지 대다수의 object 디텍터들은 backbone으로부터 추출된 multi-scale features를 직접 사용하는 반면에, FPN은 top-down 경로를 통합하여 다양한 스케일에서 features를 순차적으로 결합한다.
-
PANet, STDL, G=FRNet, NAS=FPN, Auto-FPN, EfficientDet과 다르게, Recursive Feature Pyramid는 bottom-up backbone을 반복적으로 거쳐 FPN의 표현력을 강화한다. 추가적으로 mini-DeepLab에서 디자인한 Seamless와 비슷하게 features를 풍부하게 해줄 ASPP를 통합시켰다.
-
ASPP(Atrous Spatial Pyramid Pooling)
- sementic segmentation의 성능을 높이기 위한 방법 중 하나로, DeepLab V2에서 feature map으로부터 rate가 다른 atrous convolution을 병렬로 정렬한 뒤, 이를 다시 합쳐주는 기법이다.
-
- Recursive Convolutional Network
-
많은 recursive 방법은 다양한 종류의 computer vision 문제들을 해결하기 위해 제안되어왔다. 최근에 CBNet recursive는 FPN의 인풋으로 features를 출력하기 위해 여러 backbone을 cascade하는 object detection을 제안했다.
- cascade 알고리즘은 네트워크를 계층으로 분할하고, 입력 아키텍처의 모든 계층이 학습 될 때까지 각 계층을 하나씩 학습시킨다.
-
반대로, 본 논문에서 제시하는 RFP는 효과적인 fusion modules를 포함하여 FPN을 풍부하게 해줄 ASPP의 recursive computation을 제안한다.
-
- Conditional Convolution
-
Switchable Atrous Convolution(SAC)는 어떠한 pretrained된 models이든 바꾸지 않고, 표준 convolution에서부터 조건부적인 convolution까지 효과적인 변환 메커니즘을 허용해준다. 따라서 SAC는 많은 pretrained backbone에 자유롭게 모듈의 장착과 적용이 가능하다는 뜻이다.
-
SAC는 글로벌 컨텍스트 정보와 새로운 weight locking 메커니즘을 사용하여 더 효과적이다.
-
4. Recursive Feature Pyramid
4.1. Feature Pyramid Networks
- FPN의 역사를 공부해봅시다.
-
Object Detection 분야에서 scale-invariant는 중요한 과제였다. 즉, object detection의 목적에 맞게 이미지의 크기나 회전에 불변하는 이미지 고유의 특징들을 찾는 것이다. 특히나 작은 물체를 찾기란 더욱 난제였다. 이러한 문제를 해결하고자, 이미지나 feature map의 크기를 다양한 형태로 rescale하는 접근을 해왔다. 하지만 이러한 작업은 메모리나 시간 측면에서 비효율적이기 때문에 Feature Pyramid Network(FPN)라는 방법이 등장하게 되었다.
-
다음은 FPN이 등장하기 까지의 새로운 형태의 기법들이다.
- Featurized Image Pyramid
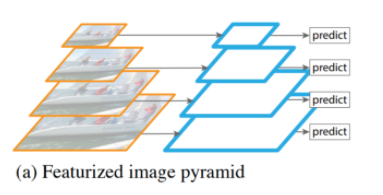
- 딥러닝이 대두하기 전에 다양한 해상도에서 feature를 추출하려고 할 때, 이미지의 크기를 rescale해서 추출하고자 한 방식이다.
- 입력 이미지 자체를 여러 크기로 resize한 뒤, 각각의 이미지에서 object detetion을 한다.
- 입력 이미지 자체를 여러 크기로 복사하기 때문에, 연산량이 크고 시간이 오래 걸리는 단점이 있다.
- Single Feature Map
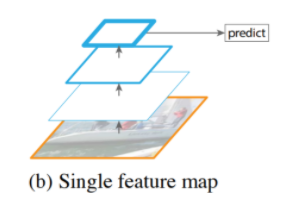
- 초기의 CNN 구조 형태로, 계속 convolution 필터를 적용하는 방식이다.
- CNN을 통과하여 얻은 최종 단계의 feature map으로 object detetion을 한다.
- multi-scale을 사용하지 않고 한번에 feature를 압축하기 때문에, 신경망을 통과할수록 이미지에 담겨져있는 정보들이 추상화되어 작은 물체들에 대한 정보가 사라지는 문제가 있다.
- Pyramidal Feature Hierarchy
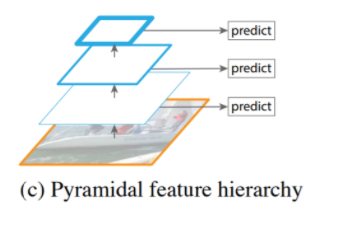
- 서로 다른 scale의 feature map을 이용하여 multi-scale feature를 추출하는 방식이다. 각 레벨에서 독립적으로 feature를 추출하여 object detetion을 하는데, 이미 계산되어 있는 상위 레벨의 feature를 재사용하지 않는다는 특징이 있다.
- SSD
- 작은 물체들에 대한 정보를 살리면서 object detection을 수행하지만, 상위 레벨에서 얻게된 abstract 정보를 활용 못하는 문제가 있다.
- Feature Pyramid Network
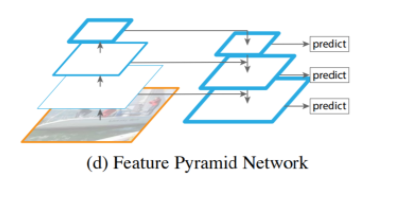
-
CNN을 통과해 feature map을 생성한다. 가장 상위 레벨에서부터 거꾸로 내려오면서 feature를 합쳐준 뒤 object detection을 수행한다.
- feature를 합치는 방식은, 기본적으로 FPN은 feature map이 layer를 통과하면서 resolution이 2배씩 작아진다. 따라서 합치기 위해 resolution을 맞춰줘야 한다. nearest neighbor upsampling 기법으로 상위 feature map의 resolution을 2배로 키워주고, 하위 feature map은 채널 수를 맞춰주기 위해 1x1 convolution을 수행한다.
-
이러한 방식은 상위 레이어의 abstract한 정보를 재사용하므로 multi-scale의 feature들을 효율적으로 사용할 수 있다. 또한, 하위 레이어의 적은 물체들에 대한 정보를 동시에 살릴 수 있다는 특징이 있다.
-
skip connection, top-down, cnn forward에서 생성되는 피라미드 구조를 합친 형태이다. forward에서는 추출된 sementic 정보들을 top-down 과정에서 upsampling하여 해상도를 높여주고, forward에서 손실된 지역적인 정보들을 skip connection으로 보충해서 스케일 변화에 강인하게 된다.
-
FPN 모델은 피라미드 계층 구조이기 때문에, 낮은 level에서 높은 level까지의 의미를 모두 갖고 있다. 크게 bottom-up 프로세스와 top-down 프로세스가 있다.
1) Bottom-up pathway
-
위로 올라가는 forward 단계로, 매 layer마다 의미 정보를 응축하는 역할을 한다. 깊은 모델의 경우 가로, 세로 크기가 같은 레이어들이 여러개 있을 수 있는데 이 경우에 같은 레이어들은 하나의 단계로 취급해서 각 단계의 맨 마지막 레이어를 skip-connection에 사용하게 된다.
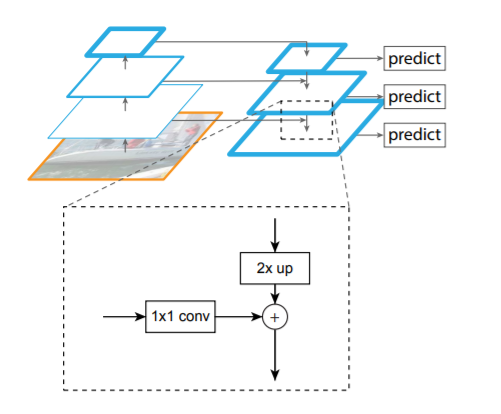
-
즉, 각 단계의 마지막 레이어의 출력을 feature map의 reference set으로 선택한다. 피라미드를 풍부하게 생성하며, 각 단계의 가장 깊은 레이어에는 가장 영향력이 있는 특징이 있어야 한다. 특히 ResNet의 경우, 각 단계의 마지막 잔차 블록(residual block)에서 출력되는 feature activation을 활성화한다.
2) Top-down pathway
-
아래로 내려가는 forward 단계로, 많은 의미 정보들을 가지고 feature map을 2배로 up-sampling하여 더 높은 해상도의 이미지를 만드는 역할을 수행한다. 여기서 skip-connection을 통해 같은 사이즈의 bottom-up 레이어와 합쳐서 손실된 지역적 정보를 보충한다.
-
top-down 과정에서 매 레이어마다 classifier/regressor가 적용되는데, 같은 classifier/regressor를 사용하기 때문에 채널이 전부 같다. 때문에 skip-connection을 합칠 때, 1x1 레이어를 한번 거쳐서 채널을 알맞게 바꿔준다.
-
-
- Featurized Image Pyramid
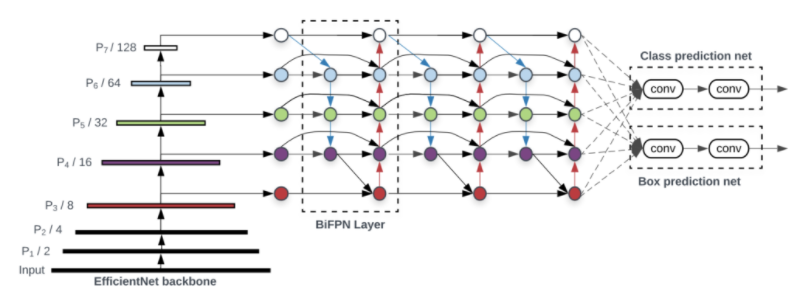
- FPN의 기법 이후, 이를 개선하기 위해 새로운 기법들이 제시 되는데, 최근 논문에서는 EfficientDet에서 제시한 BiFPN이 있다.
-
BiFPN 구조가 등장하기 전까지의 FPN의 새로운 구조들
- (a) FPN
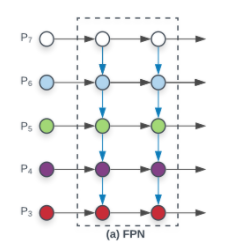
- 전통적인 FPN 구조로, top-down 방식을 사용한다.
- (b) PANet
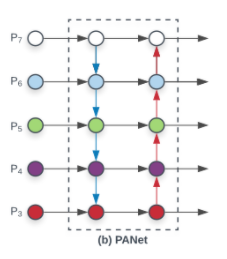
- FPN에서 bottom-up을 추가하였다.
- (c) NAS-FPN
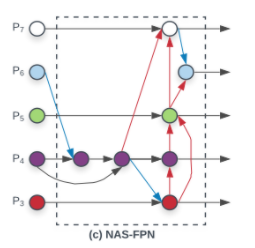
- AutoML의 Neural Architecture Search를 FPN 구조에 적용하였고, 불규칙적인 FPN 구조를 보인다. (a)와 (b)는 같은 scale에만 connection이 존재하지만, NAS-FPN부터는 scale이 다른 경우에도 connection이 존재하는 cross-scale connection을 적용한다.
- (d) Fully-connected FPN
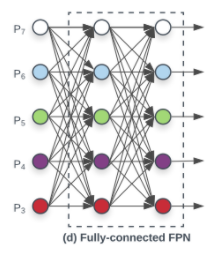
- EfficientDet 논문의 저자들이 실험한 방식으로, 정확도에서 향상되지 못하고 계산이 복잡한 단점을 가지고 있다.
- (e) Simplified PANet
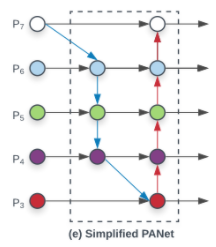
- PANet에서 input edge가 1개인 노드들은 기여도가 적을 것이라 생각하며 제거를 하여 얻은 네트워크 구조이다.
- (f) BiFPN
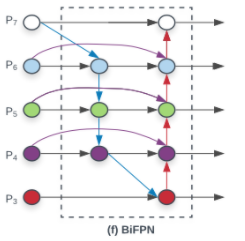
-
대망의 BiFPN은 보라색 선처럼 같은 scale에서 edge를 추가하여 더 많은 feature들이 fusion되도록 구성을 하였다.
-
PANet은 top-down과 bottom-up path를 하나씩만 사용한 반면, BiFPN은 여러 번 반복하여 사용하였다. 이를 통해 더 high-level의 fusion을 할 수 있다고 한다.
-
FPN에서 레이어마다 가중치를 주어 좀더 각각의 층에 대한 resolution 정보가 잘 녹아낼 수 있도록 하는 장치이다.
-
- (a) FPN
-
4.2. Recursive Feature Pyramid
-
본 논문에서 제시하는 FPN 구조는 RFP(Recursive Feature Pyramid) 방식이다.
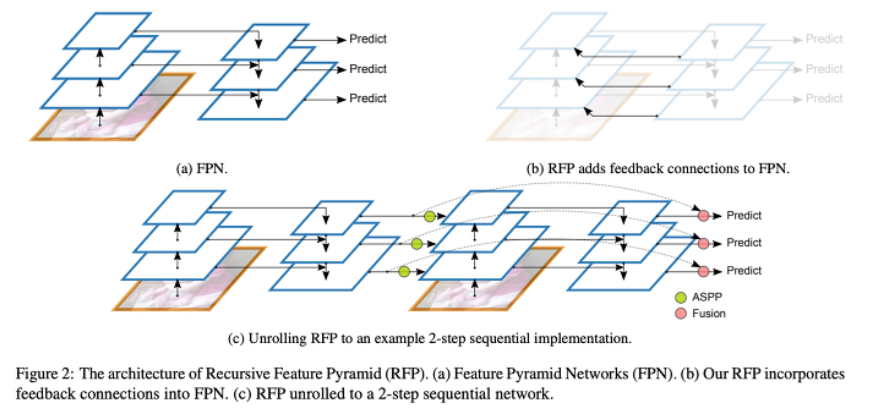
- 전통적인 (a) FPN에 recursive를 추가한 것이 (b) RFP이다. 이러한 recursive 연산을 unroll한 것이 (c)의 구조이다. ASPP를 connecting module로 사용하였고, Fusion을 output update로 사용하였다.
4.3. ASPP as the Connecting Module
-
본 논문에서는 Atrous Spatial Pyramid Pooling(ASPP)를 connecting 모듈 R로 사용했다.
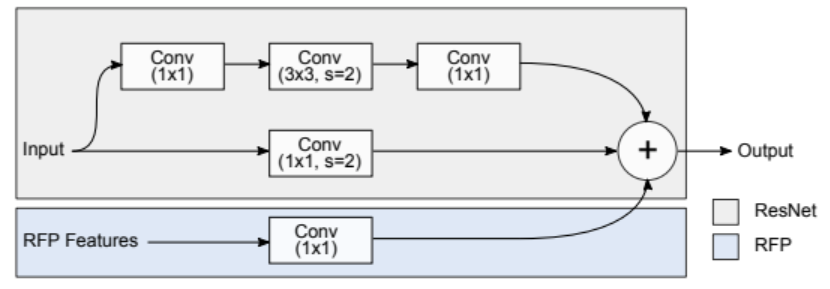
- 이 모듈에는 4개의 평행한 브랜치들로 구성되어 있다. 이들 중 3개의 브랜치는 convolution 레이어를 사용하고, ReLU 함수를 적용한다. output 채널의 수는 input 채널의 수의 1/4이다. 마지막 브랜치는 feature를 압축시키기 위해 1x1 conv와 ReLU를 사용하여 feature를 1/4로 변환해주는 GAP를 사용한다. 최종적으로, 스케일을 resize하고 나머지 3개의 브랜치들을 연결해준다.
-
ASPP를 이해하기 위해..
-
Atrous Convolution
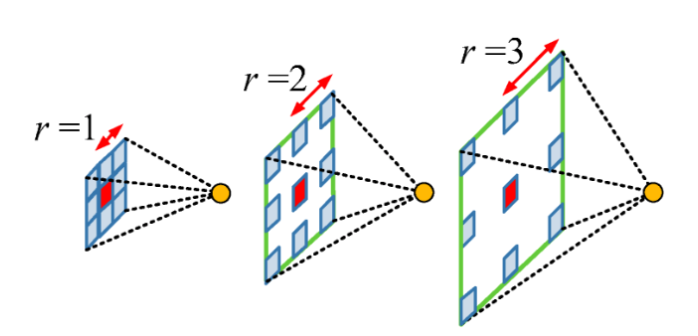
-
trous는 구멍(hole)을 의미한다. 기존 convolution과 다르게 필터 내부에 빈 공간을 둔 채 작동한다. ROI가 커질수록 빈 공간이 넓어지게 됨을 의미한다.
-
이는 기존 convolution과 동일한 양의 파라미터와 계산량을 유지해주며, field of view(한 픽셀이 볼 수 있는 영역)을 크게 가져갈 수 있게 된다. 여러 convolution과 pooling 과정에서 디테일한 정보가 줄어들고, 특성이 점점 abstract해지는 것을 방지해줄 수 있다.
-
보통 sementic segmentation에서 높은 성능을 내기 위해서는 convolutional neural network의 마지막에 존재하는 한 픽셀이 입력값에서 어느 크기의 영역을 커버할 수 있는지를 결정하는 receptive field의 크기가 중요하게 작용한다. Atrous convolution을 활용하면 파라미터의 수를 늘리지 않으면서도 receptive field를 크게 키울 수 있기 때문에, DeepLab Series에서 이를 적극적으로 활용하려고 한다.
-
-
Spatial Pyramid Pooling
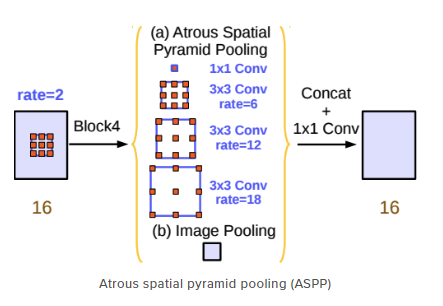
- Semantic segmentation의 성능을 높이기 위한 방법 중 하나로, spatial pyramid pooling 기법이 자주 활용되고 있다. DeepLab V2에서 feature map으로부터 여러 개의 rate가 다른 atrous convolution을 병렬로 적용한 뒤, 이를 다시 합쳐주는 ASPP 기법을 제안했다. 이러한 방식은 multi-scale context를 모델 구조로 구현하여 보다 정확한 semantic segmentation을 수행할 수 있도록 도와준다.
-
4.4. Output Update by the Fusion Module
-
Fusion 모듈은 시퀀스 데이터를 사용한다고 가정할 때, RNN의 업데이트 프로세스 과정과 유사하다. Fusion 모듈은 2에서부터 T까지 스텝으로 진행된다.
-
Fusion 모듈은 sigmoid 동작으로 진행되는 convolution layer에 의해, attention map을 계산하기 위해 사용한다. attention map 결과는 feature들의 weight를 계산하고, 업데이트하는데 사용된다.
5. Switchable Atrous Convolution
5.1. Atrous Convolution
- 위의 설명 참조
5.2. Switchable Atrous Convolution
-
본 논문에서 제시하고 있는 SAC는 다음 그림과 같은 구조를 가지며, 3가지 주요 구성(2개의 global context modules과 SAC)으로 이루어진다.
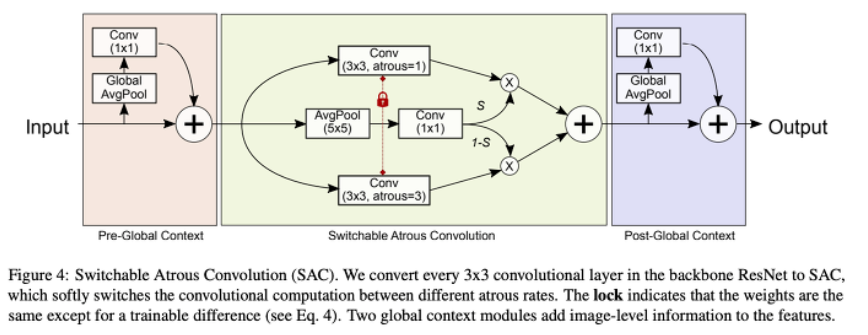
-
논문에서는 convolutional 연산을 위해, y = Conv(x, w, r) 식을 사용했다. w는 weight, r은 atrous rate, x는 input, y는 output이다. 아래와 같은 식을 통해 ResNet backbone의 convolutional layer를 SAC로 변환한다.
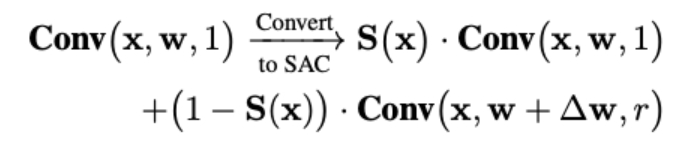
-
S(X)는 switch function이며, delta w는 trainable weight이다. S(X)는 5x5 kernel의 average pooling과 1x1 convolutional layer로 구성되어 있다. switch function은 input과 location이 독립적이기 때문에, backbone 모델은 필요에 따라 다양한 scale에 적용가능하다.
-
이러한 SAC를 통해 input이 두 가지 다른 atrous rate를 바탕으로 연산을 하면서 더욱 정확한 모델을 만들어낼 수 있다. 다시 말해, 특정 이미지를 하나의 네트워크로 하여금 다양한 관점(receptive field)으로 바라보게 함으로써 성능을 향상시켰다.
-
5.3. Global Context
-
SAC 구조를 다시 보면 SAC의 메인 컴포넌트의 앞뒤로, 2개의 global context modules를 넣은 것을 볼 수 있다. 이러한 2개의 모듈은 input feature가 GAP 레이어에 의해 먼저 압축되기 때문에 경량화된다.
-
Global context 모듈은 SENet과 비슷하지만 다음 2가지의 주요한 차이점이 있다. 차이점을 말하기 전에, SENet 간단 설명.
-
Squeeze and Excitation Networks로, SE block으로 이루어져있다. SE block은 2가지 operation으로 작동하는데, 첫 번째는 squeeze operation이다. feature map에 대한 전체 정보를 요약해주는 것으로, 각 채널들의 중요한 정보들만 추출해서 가져가겠다는 뜻이다. 채널들의 중요한 정보를 추출해주는 대표적인 기법은 GAP로, 채널 디스크립터로 압축이 가능하다.
-
두 번째는 excitation operation이다. recalibration하는 것으로, 채널간 의존성을 계산한다. fully connected layer와 non-linearity function을 조절함으로써, 각 feature map의 중요도를 0~1 사이로 스케일한다.
-
SENet은 모델 구조와 성능에 초점을 맞춘 것이 아니라, 연산량을 줄이기 위한 목적이다. 또한, 기존 네트워크에 붙이면 바로 적용이 가능하다.
-
-
차이점 1) non-linearity layers없이 one convolutional layer를 사용했다.
2) output 뒤에 Sigmoid로 re-calibraing value를 계산한 다중 input 대신에 main stream을 더했다.
6. Experiments
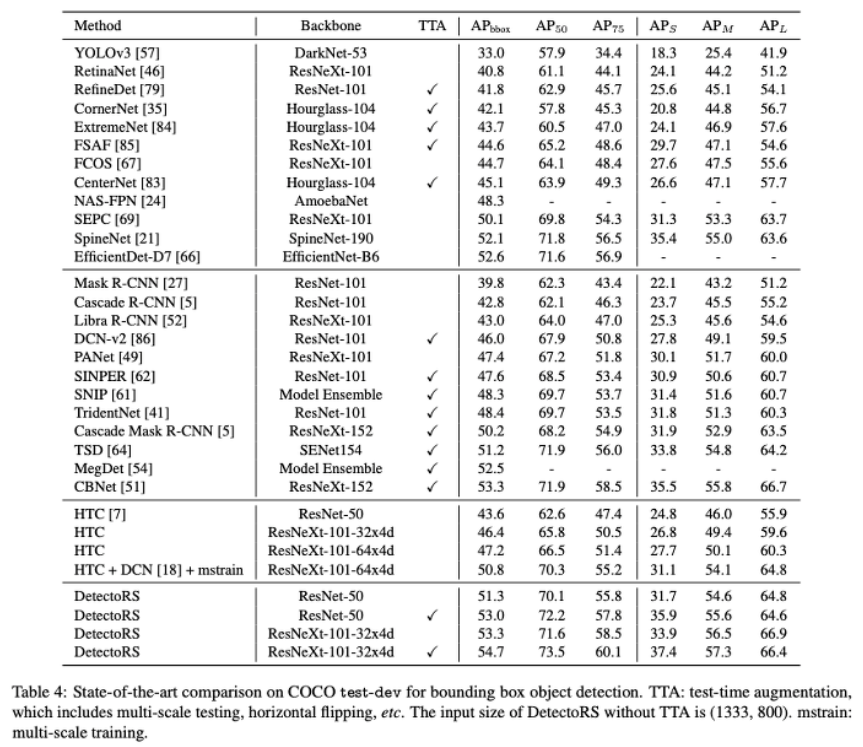
참고자료
EfficientDet : Scalable and Efficient Object Detection Review