NETNet: Neighbor Erasing and Transferring Network for Better Single Shot Object Detection
1. Abstract
-
실시간 탐지와 성능 향상을 위해, 최근 SSD가 주목받기 시작했다. 복잡한 scale variations를 해결하기 위해, SSD는 multiple pyramid layers를 기반으로 scale-aware predictions를 진행한다. 하지만, pyramid의 features는 detection performance에 제한적이기에 scale-aware가 충분하지 않다.
-
기존의 SSD는 2가지 문제가 있다. 1) samll objects are easily missed[작은 물체 탐지가 어려움]. 2) the salient part of a large object is sometimes detected as an object[큰 물체의 두드러진 부분이 물체로 탐지됨].
-
위와 같은 문제를 관측했기에, 본 논문에서는 pyramid features를 재구성하고 scale-aware features를 탐지하는 NET(Neighbor Erasing and Transferring) 매커니즘을 제안한다.
-
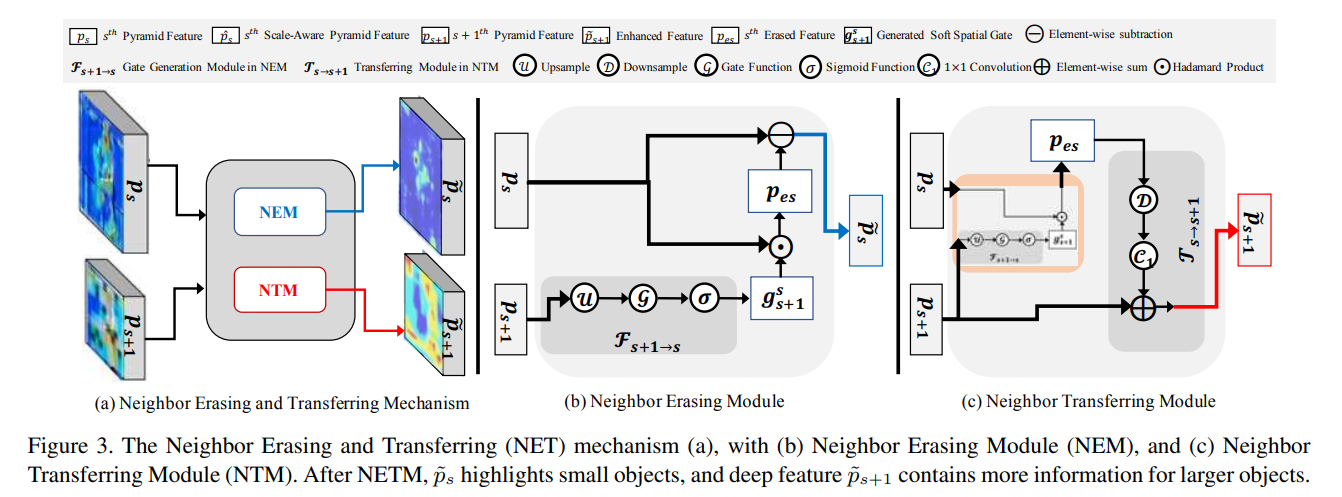
NET 매커니즘 안에는, 큰 물체의 salient features를 제거해주고 shallow layers에 작은 물체의 features를 강조해줄 수 있도록 설계된 NEM(Neighbor Erasing Module)있다. 또, 제거된 features를 변형해주고 deep layers에 큰 물체를 강조해줄 수 있는 NTM(Neighbor Transferring Module)이 있다.
2. Introduction
- 기존의 SSD는 pyramid feature representation 기반으로 개발되어졌다. 따라서 SSD는 피라미드의 서로 다른 계층 내에서 크기가 다른 객체를 감지하여 scale-aware object detection을 시행한다. 이는 deep layer의 samll feature resolution에는 large object에 대한 더 많은 의미 정보가 포함되어 있다.

-
위의 그림을 보다시피 기존의 SSD에서 작은 객체를 탐지하기 위해 사용하는 shallow features가 오히려 작은 객체의 features를 약화시키고 탐지를 방해하면서 큰 객체의 features를 주요한 특징을 지배한다. 이러한 부분들은 위의 2가지 문제를 해결하기에는 어렵다.
-
따라서 feature scale-confusion을 확장하기 위해서는 중복된 특징들을 제거해야 한다. 그러므로 본 논문에서는 shallow layers의 작은 객체의 특징들을 유지하면서, 큰 객체의 features를 제거한다.
- 본 논문의 큰 핵심은 2개의 모듈이다.
- NEM(Neighbor Erasing Module)
- shallow layers(얕은 레이어, 비교적 상단, 높은 resolution)로부터 큰 객체를 추출하고 제거하기 위한 과정을 위해 gate-guided를 반전시켰다.
- NTM(Neighbor Transfer Module)
- deep layers(깊은 레이어, 비교적 하단, 낮은 resolution)에서는 큰 객체의 features를 강조시키고 변형시킨다.
- NEM(Neighbor Erasing Module)
- SSD 네트워크를 수정한 NET 매커니즘은 scale-aware features와 scale-aware prediction을 동시에 재구성해줄 수 있다.
3. Related Work
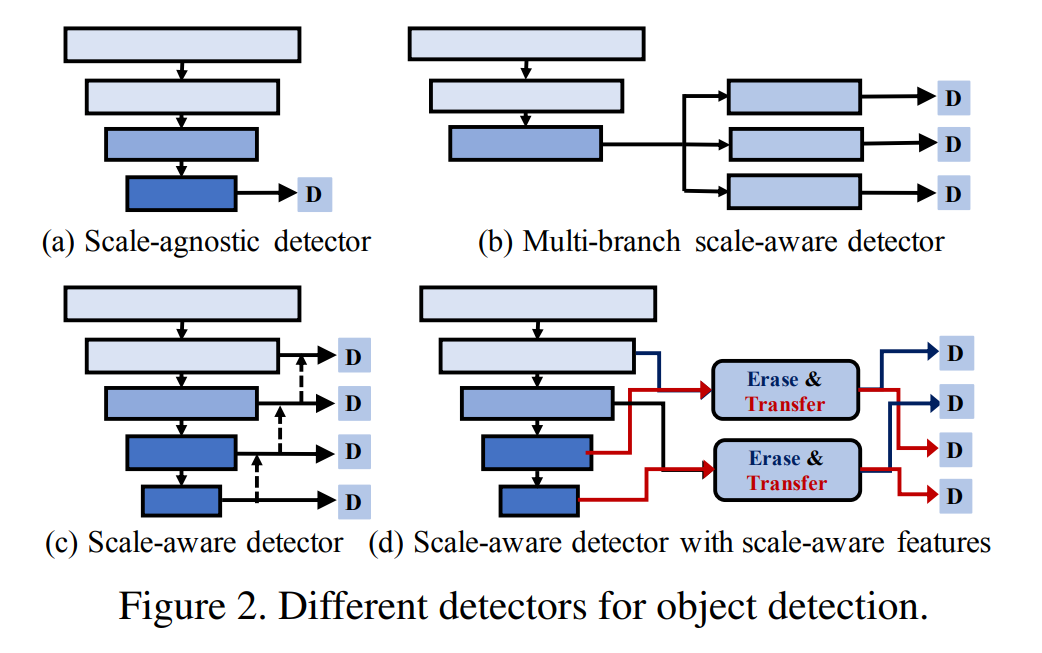
- Scale-agnostic detectors
-
two-stage 방식의 Faster R-CNN은 경량 네트워크를 제안하고 탐지 네트워크를 완전한 end-to-end 네트워크로 구성된다.
-
YOLO, Faster R-CNN, R-FCN과 같은 방법들은 detection의 정확도와 효율성을 높이기 위해 중요한 과정을 거쳐왔다. 위의 그림에서 (a)가 이러한 타입들로, 가장 깊은 single-scale의 high-level features를 활용한다. 그러므로 이러한 디텍터들은 scale-agnostic detectors(스케일로부터 자유로운 디텍터들)이다.
-
- Scale-aware detectors
- 복잡한 scale의 다양성으로 인해, 많은 연구원들은 multi-scale pyramid features를 연구하였다. SSD는 이러한 multi-scale pyramid features를 기반으로 한 scale-aware prediction을 제안했다.
-
위의 2가지 방법과 다르게 본 논문에서는 erasing과 transferring 매커니즘으로 만들어 scale-aware features를 위한 SSD를 제안한다.
-
adversarial erasing strategy는 객체들의 위치 파악이 약할 뿐만 아니라, semantic segmentation과 salient object detection에서도 약하다는 것을 발견하였다. 이러한 방식은 인식이 잘된 영역은 지우고 다시 반복하는 작업이지만, 이와 반대로 상관성이 없는 특징을 지우는 것이 핵심이다.
- shallow layers에서 지워진 features는 deep layers의 feature를 향상시키기 위해 지워지는 대신에 transferred된다.
4. NET Mechanism
-
기존의 방식에서는 큰 객체의 features가 현저할수록, 작은 객체는 사라지는 것을 볼 수 있다. 따라서 NET 매커니즘으로 basic pyramid features를 scale-aware object detection을 위한 scale-aware features로 재구성했다.
-
NEM은 shallow layers로부터 큰 객체의 features를 삭제하고, 작은 객체의 features를 강조시키기 위해 설계되었다.
-
NTM은 deep features를 강화하기 위해 이러한 features를 transfer하기 위해 사용된다.
4.1. Basic Feature Pyramid
-
모든 스케일 변수 S를 위한 객체들은 X = {x1, x2, …, xs}로 표현된다. 즉, x1은 가장 작은 scale을 나타내는 객체고, xs는 가장 큰 scale을 가진 객체이다.
-
SSD는 피라미드 계층 구조로 객체를 탐지하기 때문에, 각각의 CNN의 레이어들은 특정한 scale의 객체를 탐지해야만 한다.
-
S번째 layer의 features를 ps라고 한다면, 모든 피라미드 features는 P = {p1, p2, …, ps}로 나타낼 수 있다. 즉, p1은 작은 객체인 x1을 탐지하기 위한 shallow layer가 있는 가장 큰 해상도에 있는 feature이다.
-
피라미드 계층 구조에서는 분명하게도, shallow에서 deep layer로 갈수록 점차적으로 작은 객체의 정보가 손실된다. SSD의 작은 input image때문에, deep layers는 큰 객체를 위한 features만을 포함한다.
-
따라서 다음 식과 같이, shallow layer의 feature scale-confusion(다양한 scale의 객체에 대한 feature를 포함하여)는 작은 객체를 탐지하기 어렵게 만들고, 부분 탐지로만 이어진다.
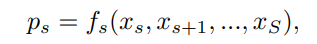
4.2. Neighbor Erasing Module
-
scale-confusion을 해결하고자, NEM을 통해 중복된 features를 걸렀다.
-
피라미드 layer에서 s번째와 (s+1)번째 layer를 가정해보자. s번째 layer의 featurs는 ps = fs(xs, x_s+1, …, xS)로, (s+1)번째 layer의 features의 p_s+1 = f_s+1(x_s+1, …, xS)에 비해 객체 xs에 대한 정보를 많이 가지고 있다. 이러한 feature distribution에 기반하여 본 논문에서는 pes = fs(x_s+1, …, xS) features를 지운 피라미드 feature ps로부터 얻은 scale s의 객체를 위한 ~ps = fs(xs)라는 features를 만들었다.
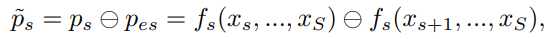
-
ps로부터 pes feature를 추출한 식은 다음과 같다.
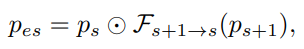
-
위의 식에서 오른쪽 항은 다음 식과 같다.
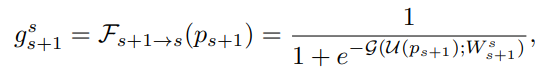
-
U로 표시된 변수는 upsampling으로, gate g_s+1와 features ps 사이에 일관된 spatial resolution을 유지하기 위해 사용되었다. G는 self-attention function을 표현하기 위한 변수로, input features에서 추출할 수 있으며 spatial attention 매커니즘을 기반으로도 구성할 수 있다.
-
spatial attention map을 만들기 위해 max pooling 또는 average pooling을 사용했다.
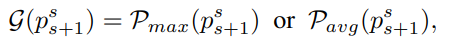
-
정밀도와 효율성 사이의 최적 절충안이 입증되었기 때문에 1x1 conv를 사용했다.
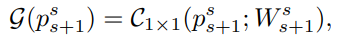
-
요약하자면, 반전된 gate를 통해 큰 객체의 features를 압축시킴으로써 작은 객체 xs를 위한 scale-aware features인 ~ps를 만들었다.
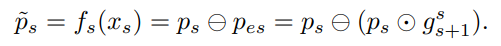
4.3. Neighbor Transferring Module
-
피라미드 feature ps는 {x_s+1, x_s+2, …, xS}의 디테일한 정보를 포함하고 있다. 이러한 정보들은 작은 객체 xs를 탐지하는데 방해될 수 있지만, classification과 localization의 정확도를 위한 큰 객체들의 features를 강화하기에 도움이 될 수 있다. 따라서 NTM을 이용해 shallow layer로부터 deep layer로 이러한 feature를 transfer한다.
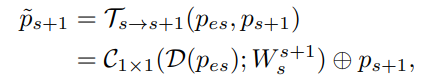
5. Single-Shot Detector: NETNet
-
basic pyramid를 기반으로 NET 모듈을 만들어 scale-aware features를 만들었고, 앞서 말한 scale 문제들을 해결했다. Implementation에서는, detection anchos를 구성하고 ground truth를 할당하는 과정에서 가장 가까운 neighbor pyramid levels 사이에 scale-overlap이 있었다. 이를 방지하고자, NETM skip manner를 만들었다.
-
또한, scale-overlap이 가장 가까운 인접 피라미드 레이어에 존재하는 하나의 객체에 대한 feature를 보완한다는 점을 고려하여, NNFM(Nearest Neighbor Fusion Module)을 도입한다.
-
NNFM 및 NETM를 기반으로 한 box regression 및 classification을 위한 6개의 다른 detection head는 scale-aware detector NETNet을 구성하기 위한 scale-aware features를 기반으로 구축되었다.
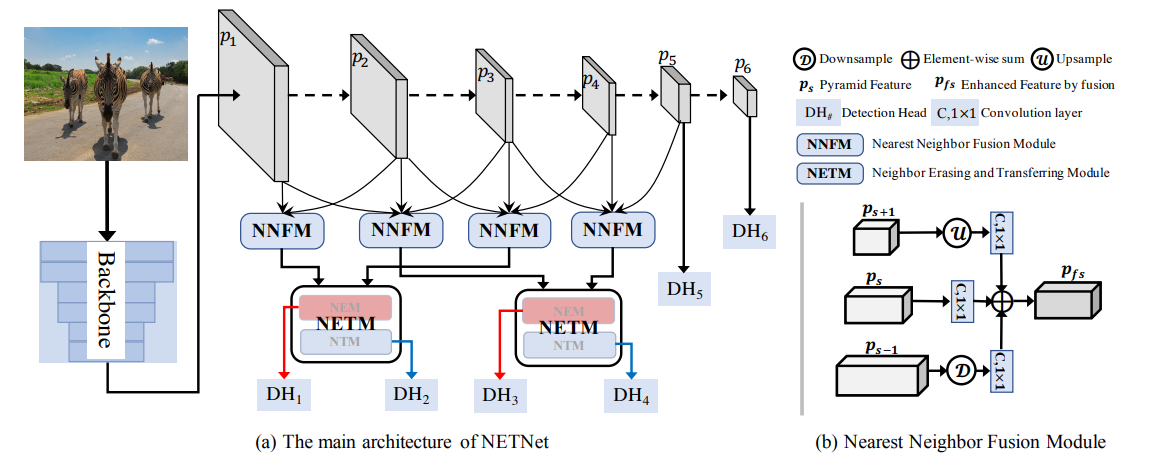
5.1. NETM(NTM + NEM) in a Skip Manner
-
작은 객체를 탐지하기 위해 사용되었던 shallow layers(38x38 resolution)의 features와 반대로, 큰 객체를 탐지하기 위해 deeper layers(10x10 resolution)를 사용했다. 왜냐하면 small resolution(3x3)은 큰 receptive fields를 가지고 있고 적은 spatial 정보를 가지고 있기 때문이다. 따라서 우리는 p5와 p6의 features를 사용하지 않고 feature를 erasing하고 transferring하는 2개의 NETM을 만들었다.
-
하나의 작은 객체는 p1과 p2에 동시에 탐지될 수 있는데, 이를 피하고자 2개의 skipped NETM을 이용하여 오버랩된 부분을 방해한다.
5.2. NNFM(Nearest Neighbor Fusion Module)
-
feature 피라미드의 연구에서 지적했듯이, 인접한 피라미드 레이어의 feature는 상호보완적이다. 따라서 서로 다른 레이어의 context 정보를 통합하면 feature 표현이 촉진된다.
-
일반적으로 feature 피라미드를 구축하기 위해 위에서부터 아래로 features를 결합한다. 그러나 우리의 목적은 shallow 레이어에서 큰 객체의 feature는 제거하고, scale-aware features를 생성하는 것이므로, 다른 scale feature를 도입하면 scale-confusion 문제를 증가시킨다. 따라서, feature pyramid를 향상시키기 위해 보다 효과적인 융합 모듈인 NNFM을 제안한다.
-
H_s-1은 pooling layer와 1x1 conv layer로 구성되고, Hs는 1x1 conv layer로 구성된다. H_s+1은 bilinear upsampling layer와 1x1 conv layer로 구성된다.
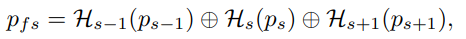
-
top-down 방식처럼 {p6, p5, p4, p3, p2} features를 사용하는 대신에, p1, p2, 그리고 p3로부터 완전한 정보를 집계시킴으로써 p2 feature를 강화시켰다.
-
작은 객체의 정보 p1은 pooling 명령과 큰 객체 p3 정보로부터 NEM 다음에 삭제된다. 결과적으로, 객체의 features는 p2에서 감지되고 NNFM의 보완적인 정보를 융합하여 강화시킨다.
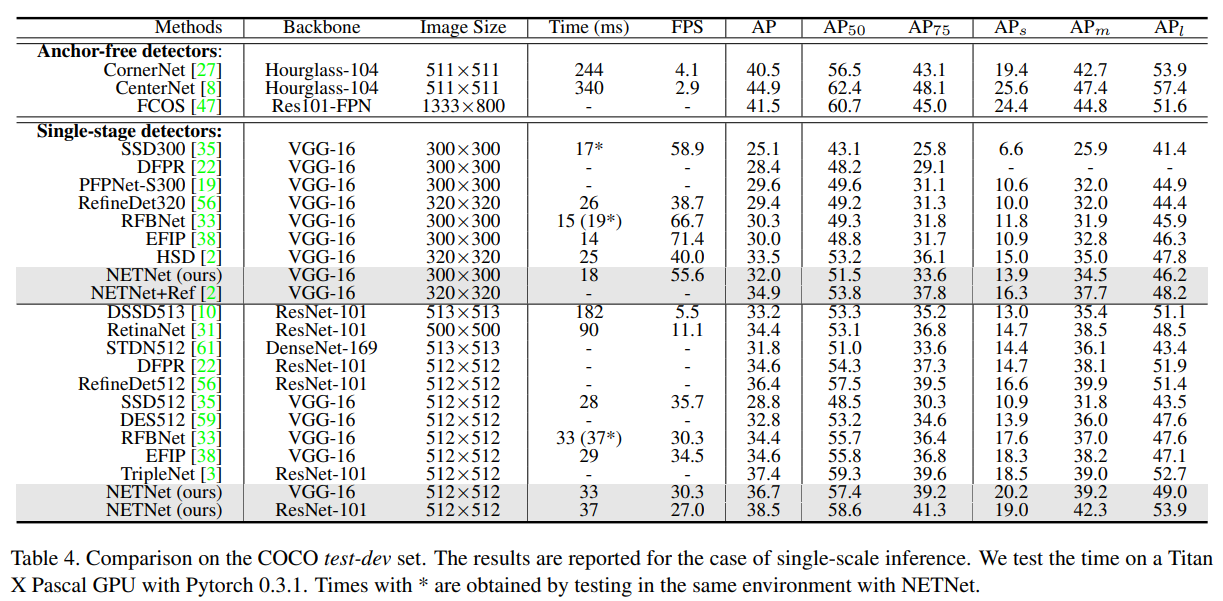
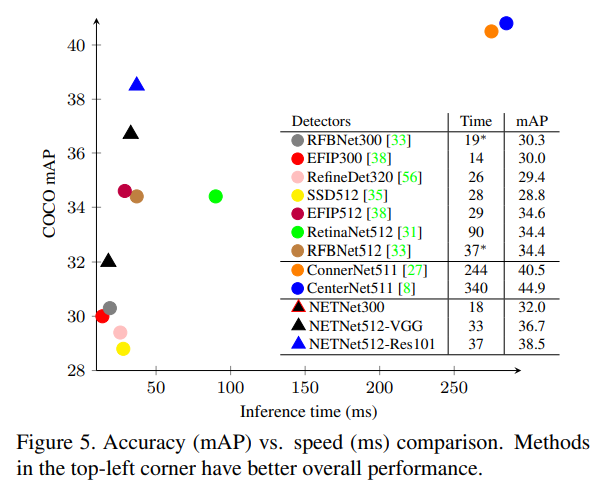
6. Experiments