5. Artificial Neural Networks(ANN)
5.1. ANN Theory
- 퍼셉트론(Perceptron)
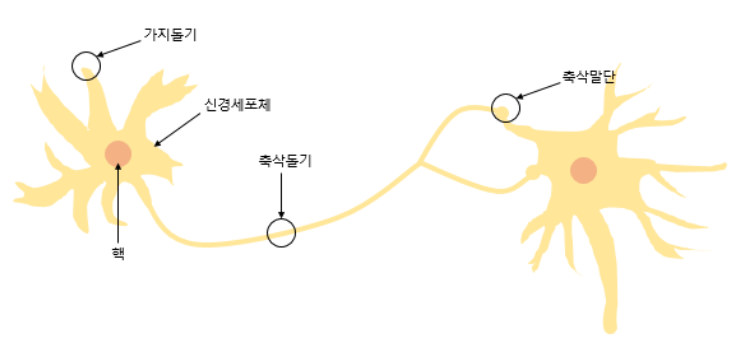
- 퍼셉트론은 초기 형태의 인공신경망으로 다수의 입력으로부터 하나의 결과를 내보내는 알고리즘이다.
- 퍼셉트론은 실제 뇌를 구성하는 신경 세포 뉴런의 동작과 유사핟.
- 다수의 입력을 받는 퍼셉트론은 다음과 같이 입력값과 출력값이 있다. x는 입력값을, W는 가중치를, y는 출력값을 의미하며, b는 bias이다.
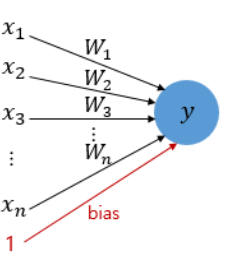
- 각각의 입력값에는 각각의 가중치가 존재하는데, 가중치의 값이 클수록 해당 입력값이 중요하다는 것을 의미한다.
- 이러한 뉴런에서 출력값을 변경시키는 함수를 활성화 함수(Actication Function)이라고 한다.
- 초기 인공신경망 모델은 활성화 함수를 계단함수를 사용하였지만, 그 외에도 다양한 함수를 사용하기 시작했다(시그모이드, 소프트맥스).
- 초기 인공신경망 모델은 활성화 함수를 계단함수를 사용하였지만, 그 외에도 다양한 함수를 사용하기 시작했다(시그모이드, 소프트맥스).
- 단층 퍼셉트론(Singl-Layer Perception)
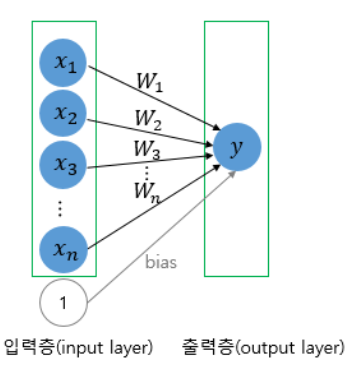
- 퍼셉트론은 단층 퍼셉트론과 다층 퍼셉트론으로 나누어지는데, 단층 퍼셉트론은 값을 보내는 단계와 값을 받아서 출력하는 2개의 단계로만 이루어진다.
- 각 단계를 층(layer)이라고 부르며, 입력층(input layer)과 출력층(output layer)이 있다.
-
단층 퍼셉트론을 이용한 논리 게이트 연산자
1) AND 게이트 : 두 개의 입력값이 모두 1인 경우에만 출력값이 1이 나오는 구조
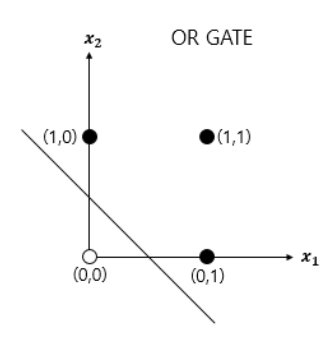
def AND_gate(x1, x2): w1=0.5 w2=0.5 b=-0.7 result = x1*w1 + x2*w2 + b if result <= 0: return 0 else: return 12) OR 게이트 : 두 개의 입력이 모두 0인 경우에 출력값이 0이고, 나머지 경우에는 모두 출력값이 1인 구조
def OR_gate(x1, x2): w1=0.6 w2=0.6 b=-0.5 result = x1*w1 + x2*w2 + b if result <= 0: return 0 else: return 1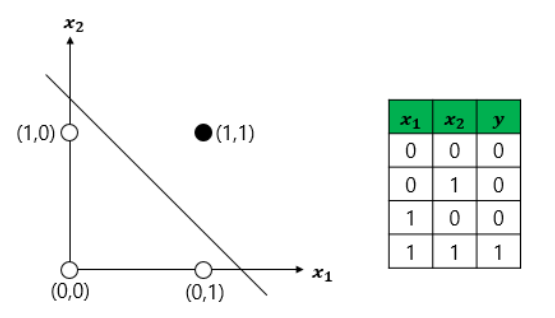
- 이외에도 논리 게이트를 충족시키는 다양한 가중치와 편향의 값이 있다.
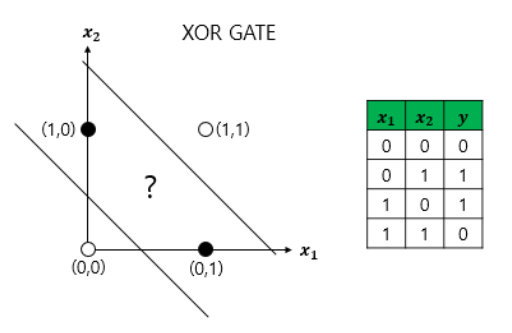
- 하지만 단층 퍼셉트론으로는 XOR 게이트를 구현할 수 없다.
- XOR 게이트는 입력값 두 개가 서로 다른값을 가지고 있을 때만 출력값이 1이 되고, 입력값 두 개가 서로 같은 값을 가지면 출력값이 0이 되는 구조이다.
-
즉, 단층 퍼셉트론은 직선 하나로 두 영역을 나눌 수 있는 문제에 대해서만 구현이 가능하지만, XOR 게이트는 두 개의 직선이 필요하다.
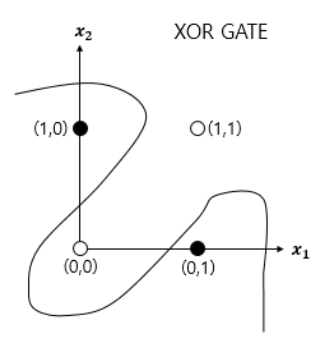
- XOR 게이트는 직선이 아닌 곡선, 비선형 영역으로 분리하면 구현이 가능하다.
- 다층 퍼셉트론(Multilayer Perceptron, MLP)
-
입력층과 출력층 사이에 하나 이상의 중간층이 존재하는 신경망으로 다음 그림에 나타낸 것과 같은 계층구조를 갖는다.
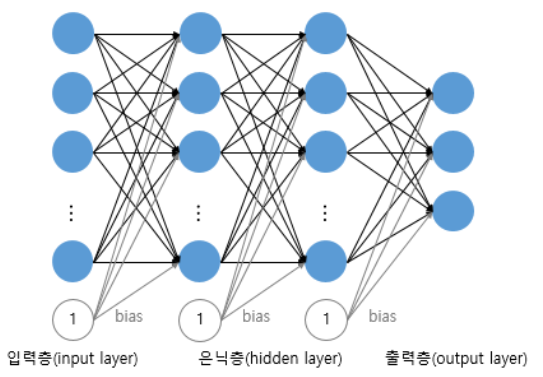
- 이 때, 입력층과 출력층 사이의 중간층을 은닉층(hidden layer) 이라 부른다.
- Multilayer perceptron은 단층 perceptron과 유사한 구조를 가지고 있지만 중간층과 각 unit의 입출력 특성을 비선형으로 함으로써 네트워크의 능력을 향상시켜 단층 퍼셉트론의 여러 가지 단점들을 극복했다.
- Multilayer perceptron은 층의 갯수가 증가할수록 perceptron이 형성하는 결정 구역의 특성은 더욱 고급화된다.
- 이와 같이 은닉층이 2개 이상인 신경망을 심층 신경망(Deep Neural Network, DNN)이라고 한다.
-
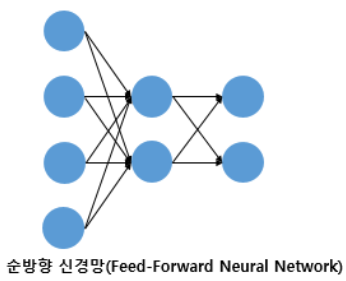
- 순방향 신경망(Feed-Forward Neural Network, FFNN)
- 다층 퍼셉트론(MLP)과 같이 입력층에서 출력층 방향으로 연산이 전개되는 신경망을 FFNN이라 한다.
-
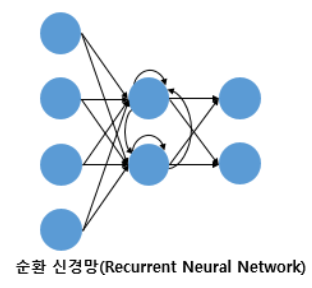
별도로 정의되는 이유는 은닉층의 출력값이 다시 은닉층의 입력으로 사용되는 재귀적인 구조를 가진 RNN이 있기 때문이다.
- 전결합층(Fully-connected layer, FC, Dense layer)
- 다층 퍼셉트론의 은닉층과 출력층에 있는 모든 뉴런은 이전 층의 모든 뉴련과 연결되어 있다.
- 이와 같이 어떤 층의 모든 뉴런이 이전 층의 모든 뉴런과 연결되어 있는 층을 전결합층이라 하며, 모든 은닉층과 출력층이 전결합층이다.
- 밀집층(Dense layer)이라고도 한다.
-
활성화 함수(Activation Function)
1) 선형/비선형 함수
- 선형 함수는 출력이 입력의 상수배만큼 변하는 직선을 그리는 함수이고, 비선형 함수는 직선 1개로는 그릴 수 없는 함수이다.
- 인공신경망의 성능을 높이기 위해서는 은닉층을 추가해야 하는데, 활성화 함수를 선형 함수를 사용하게 되면 은닉층을 쌓을 수 없게 된다. 예를 들어 f(x) = Wx라 할 때, 은닉층을 2개 추가한다고 하면 출력층을 포함해서 y(x) = f(f(f(x)))가 되며 이는 선형적인 구조임을 알 수 있다. 즉, 선형 함수로 은닉층을 추가하더라도, 1회 추가한 것과 차이를 줄 수 없다.
- 그렇다고 선형 함수를 사용한 층이 의미가 없다는 것은 아니다. 학습 가능한 가중치가 추가로 생긴다는 점에서 분명히 의미가 있다.
- 활성화 함수를 사용하는 일반적인 은닉층을 선형층과 대비되는 표현을 사용하면 비선형층이다.
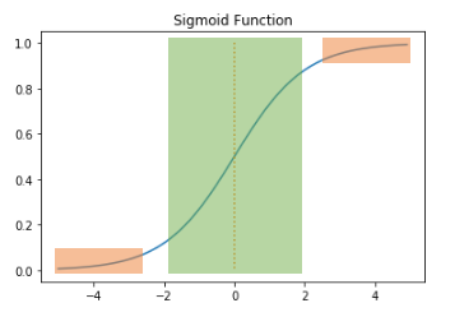
2) 시그모이드 함수
- 일반적인 인공신경망의 학습 과정은, 우선 입력에 대해서 순전파(forward propagaion) 연산을 하고, 그리고 순전파 연산을 하고 나온 예측값과 실제값의 오차를 손실 함수(loss function)을 통해 계산하고, 그리고 이 손실(loss)을 미분을 통해서 기울기(gradient)를 구하고, 이를 통해 역전파(back propagation)를 수행한다.
- 시그모이드 함수의 문제점은 미분을 하며 기울기를 구할 때 발생한다. 시그모이드 함수의 출력값이 0 또는 1에 가까워지면, 그래프의 기울기가 완만해지는 모습을 보여준다.
- 역전파 과정에서 0에 가까운 기울기가 곱해지면, 기울기 소실(Vanishing Gradient) 문제가 발생한다. 즉, 시그모이드 함수를 사용하는 은닉층의 개수가 다수가 될 경우에는 0에 가까운 기울기가 계속 곱해지면 앞단에서는 거의 기울기를 전파받을 수가 없게 되어 가중치가 업데이트가 되지 않아 학습되지 않는다.
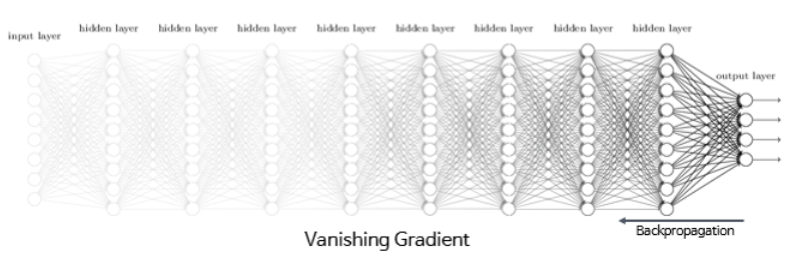
3) 하이퍼볼릭탄젠트 함수(Hyperbolic tangent function)
- 하이퍼볼릭탄젠트 함수는 입력값을 -1과 1 사이의 값으로 변환한다.
- 이 함수 역시 시그모이드 함수와 같은 문제가 발생하지만, 시그모이드 함수와는 달리 0을 중심으로 하고 있기 때문에 반환값의 변환폭이 더 크다.
- 따라서 기울기 소실 현상이 적은 편이다.
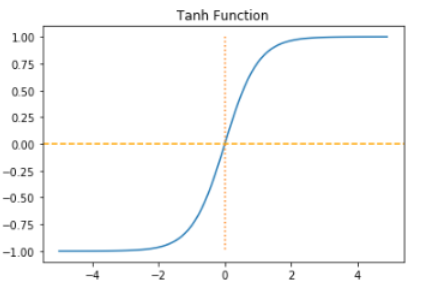
4) 렐루 함수(ReLU)
- 가장 많이 사용되고 있는 함수
- f(x) = max(0, x)로 간단하다.
- 렐루 함수는 음수를 입력하면 0을 출력하고, 양수를 입력하면 입력값을 그대로 반환한다. 렐루 함수는 특정 양수값에 수렴하지 않으므로 깊은 신경망에서 시그모이드 함수보다 훨씬 더 잘 작동한다. 뿐만 아니라, 다른 연산보다 속도가 빠르다.
- 문제는 입력값이 음수이면 기울기가 0이 되기 때문에, 이 뉴런은 다시 회생이 불가능하다. 이 문제를 죽은 렐루(dying ReLU)라고 한다.
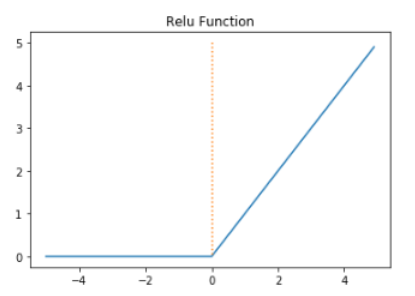
5) 리키 렐루(Leaky ReLU)
- 죽은 렐루를 보완하기 위한 함수
- 입력값이 음수일 경우에 0이 아니라 0.0001과 같은 매우 작은 수를 반환한다.
- f(x) = max(ax, x)로 간단하다. a는 하이퍼파라미터로 Leaky 정도를 결정하며 일반적으로 0.01의 값을 가진다.
6) 소프트맥스 함수(Softmax function)
- 분류 문제에서 자주 사용되는 함수
- 시그모이드 함수처럼 출력층의 뉴런에서 주로 사용되는데, 시그모이드 함수가 두 가지 선택지 중 하나를 고르는 이진 분류(Binary Classification) 문제에 사용된다면, 소프트맥스 함수는 다중 클래스 분류(Multiclass Classification) 문제에서 주로 사용된다.
- 손실 함수(Loss function)
- 손실 함수는 실제값과 예측값의 차이를 수치화해주는 함수이다.
- 오차가 클수록 손실 함수의 값은 크고, 오차가 작을수록 손실 함수의 값은 작아진다.
-
회귀에서는 평균 제곱 오차(MSE), 분류에서는 크로스 엔트로피(Cross-Entropy)를 주로 사용한다.
1) MSE(Mean Squared Error)
- 오차 제곱 평균을 의미하며, 연속형 변수를 예측할 때 사용한다.
2) 크로스 엔트로피(Cross-Entropy)
- 낮은 확률로 예측해서 맞추거나, 높은 확률로 예측해서 틀리는 경우 손실이 더 크다.
- 이진 분류의 경우 binary_crossentropy를 사용하며, 다중 클래스 분류의 경우 categorical_crossentropy를 사용한다.
- 옵티마이저(Optimizer)
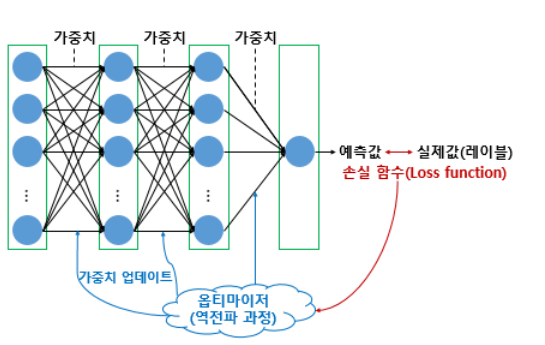
- 손실 함수의 값을 줄여나가면서 학습하는 방법은 어떤 옵티마이저를 사용하느냐에 따라 달라진다.
- 배치(Batch)는 가중치 등의 매개변수의 값을 조정하기 위해 사용하는 데이터의 양을 말한다.
- 전체 데이터를 가지고 매개변수의 값을 조정할 수도 있고, 정해준 양의 데이터만 가지고도 매개변수의 값을 조장할 수 있다.

1) 경사 하강법(Gradient Descent)
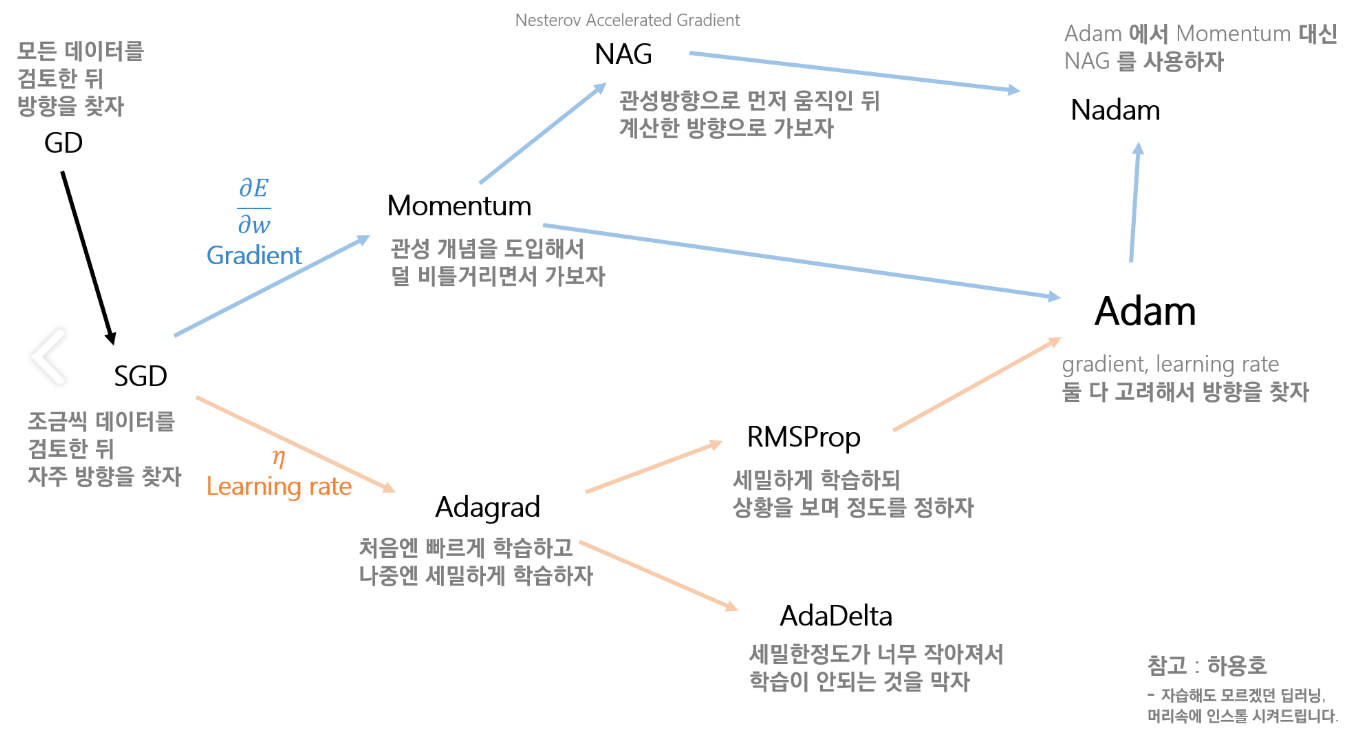
- 경사 하강법은 1차 근사값 발견용 최적화 알고리즘으로, 함수의 기울기를 구하여 기울기가 낮은쪽으로 계속 이동시켜서 극값에 이를 때까지 반복시키는 것이다.
- 최적화할 함수 f(x)에 대해, 먼저 시작점 X0를 정한다. 현재 X(i)가 주어질 때, 그 다음으로 이동할 점인 X(i+1)은 다음과 같다.
- Gamma는 이동할 거리를 조절하는 매개변수로, 딥러닝에서는 learning rate라고 생각하면 된다. 즉, learning rate가 작으면 학습 속도가 느리지만 시간이 다 되어 덜 끝날 수도 있고, learning rate가 크면 속도가 빠르지만 제대로 학습을 못할 수도 있다.
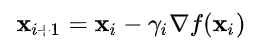

1-1) 배치 경사 하강법(Batch Gradient Descent)
- 배치 경사 하강법은 옵티마이저 중 하나로 오차를 구할 때 전체 데이터를 고려한다.
- 머신러닝에서 1번의 훈련 횟수를 1 에포크라고 하는데, 배치 경사 하강법은 한 번의 에포크에 모든 매개변수 업데이트를 한 번 수행한다.
- 배치 경사 하강법은 전체 데이터를 고려해서 학습하기 때문에, 에포크당 시간이 오래 걸리고 메모리를 많이 잡아먹지만, 글로벌 미니멈을 찾을 수 있다.
model.fit(X_train, y_train, batch_size=len(trainX))
1-2) 확률적 경사 하강법(Stochastic Gradient Descent)
- 기존의 경사 하강법의 시간이 오래 걸리는 단점을 보완하기 위해, 매개변수 값을 조정 시 전체 데이터가 아니라 랜덤으로 선택한 하나의 데이터에 대해서만 계산한다.
- 매개변수의 변경폭이 불안정하고, 배치 경사 하강법보다 정확도가 낮을 수 있지만, 속도는 빠르다.
model.fit(X_train, y_train, batch_size=1)
1-3) 미니 배치 경사 하강법(Mini-Batch Gradient Descent)
- 정해진 양에 대해서만 계산하여 매개변수의 값을 조정하는 경사 하강법
- batch_size 인자를 넘겨 mini batch 사이즈를 결정하고, mini batch 사이즈의 데이터마다 손실 함수를 만들어 gradient를 계산하여 파라미터를 업데이트한다.
- 전체 데이터를 계산하는 것보다 빠르며, SGD보다 안정적임.
- 가장 많이 사용되는 경사 하강법이다.
model.fit(X_train, y_train, batch_size=32) #32를 배치 크기로 하였을 경우
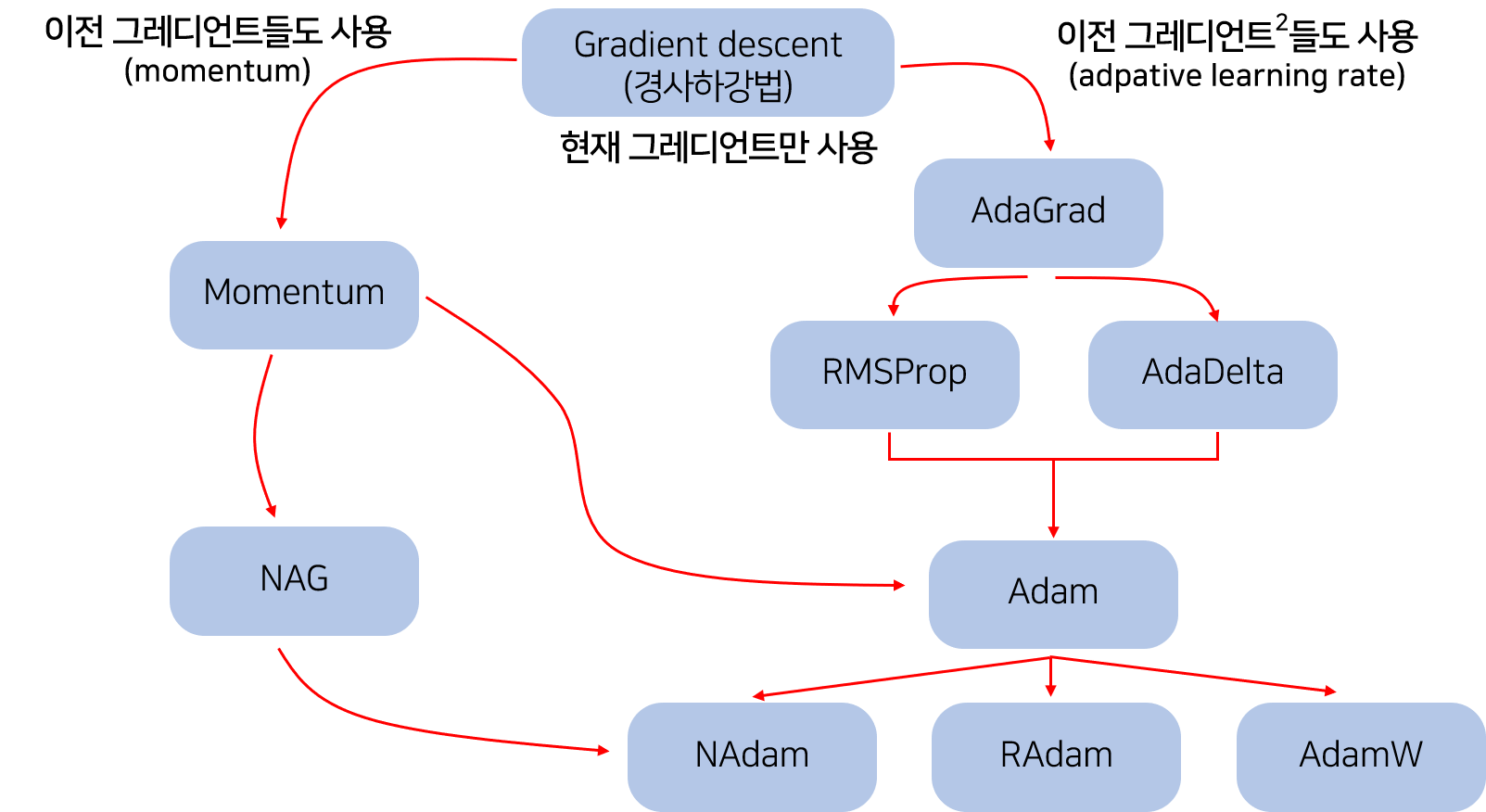
2) 모멘텀(Momentum)
- 모멘텀은 관성이라는 물리학의 법칙을 응용한 방법
- SGD에서 계산된 접선의 기울기에 한 시점(step) 전의 접선의 기울기값을 일정한 비율만큼 반영한다.
- 즉, 현재 파라미터를 업데이트할 때, 이전의 기울기(gradient)들도 포함해서 계산한다.
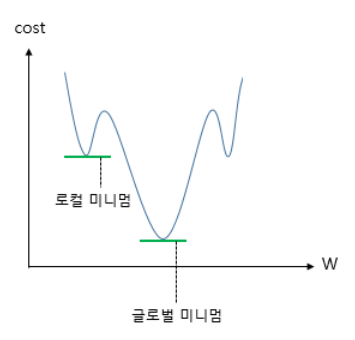
- 이러한 방식은 로컬 미니멈에 도달하였을 때, 기울기가 0이라서 기존의 경사 하강법이라면 글로벌 미니멈으로 잘못 인식하여 계산하였지만, 모멘텀을 이용하여 조절하면 로컬 미니멈에서 탈출하는 효과를 얻을 수 있다.
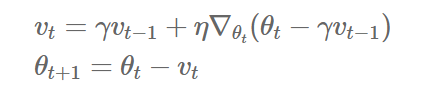
- theta를 미지수로 갖는 목적함수 J(thetha)
- learning rate를 나타내는 gamma
- 이전 gradient들의 영향력을 매 업데이트마다 r(momentum)배씩 감소시킨다.
keras.optimizers.SGD(lr=0.01, momentum=0.9)
3) NAG(Nesterov accelerated gradient)
- 모멘텀을 사용한 SGD에서 관성의 성질에 따라 글로벌 미니멈을 향해 앞으로 나아가는 것은 굉장히 좋지만, 밑면에 다다랐을 때쯤 앞에 압정이 있는 것을 발견하더라도 관성 때문에 앞으로 나아가다가 박혀버리는 꼴이 발생할 수 있다.
- NAG는 이러한 문제를 해결하기 위해 앞을 미리 보고 현재의 관성을 조절하여 업데이트 크기를 바꾸는 방식이다.
- 현재의 위치에서 미래의 위치를 계산하기 위해 목적함수의 theta를 아래와 같이 변경해준다.
- 따라서 Momentum 방식의 빠른 이동에 대한 장점을 가지면서, 적절한 시점에 멈추면서 동작하여 더욱 효과적으로 이동한다.
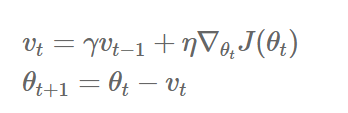
4) Adagrad
- 지금까지의 방법은 모든 파라미터에 대해 같은 learning rate를 적용한다는 점이다. 하지만, 동일한 학습률을 적용하는 것은 비효율적이다.
- 비효율적인 이유는, 예를 들어 A, B, C 레이어 중 B의 레이어가 주로 0값이 많이 나온다고 가정하자. 그러면 B에 해당하는 가중치의 값은 자연스럽게 0이 되면서 손실 함수에서도 Wb의 값의 term이 없어질 것이다. 문제는 이후에 데이터가 업데이트 되어서 0이 아닌 B의 값이 등장하게 되면 그동안 상대적으로 Wb의 값이 조금 업데이트되었기 때문에 글로벌 미니멈 지점까지 한참 남은 상태이다. 따라서 가가 파라미터의 업데이트 빈도 수에 따라 업데이트 크기를 다르게 해주는 것이 효율적일 수 있다.
- 각 매개변수에 서로 다른 학습률(learning rate)을 적용한다.
- 변화가 많은 매개변수는 학습률이 작게 설정되고, 변화가 적은 매개변수는 학습률을 높게 설정한다.
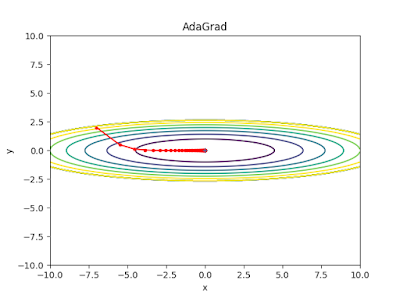
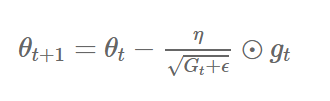
- Adagrad는 위에 있는 iteration(t)이 증가하면서 learning rate가 작아진다는 문제가 있다.
keras.optimizers.Adagrad(lr=0.01, epsilon=1e-6)
5) Adadelta
- Adadelta는 Adagrad의 learning rate의 소실 문제를 해결하기 위한 알고리즘이다.
- 이전의 모든 gradient의 정보를 저장하는 것이 아니라, 이전의 크기 w(window)개의 gradient의 정보만을 저장한다.
- 또한, gradient의 제곱의 합을 저장하지 않고, gradient의 제곱에 대한 기댓값을 저장한다.
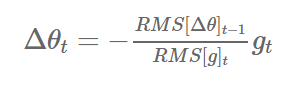
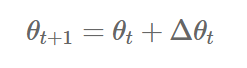
keras.optimizers.Adadelta(lr=1.0, rho=0.95, epsilon=None, decay=0.0)
6) RMSprop
- RMSprop 역시 Adagrad의 learning rate의 소실 문제를 해결하기 위한 알고리즘이다.
- 일반적으로 순환 신경망(RNN)에서 자주 사용된다.
- 이전의 정보의 업데이트는 가중치를 적게 부여하고, 최근 업데이트에는 가중치를 많게 부여하는 형태이다.
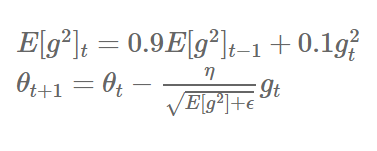
keras.optimizers.RMSprop(lr=0.001, rho=0.9, epsilon=None, decay=0.0)
7) Adam(Adaptive Moment Estimation)
- Adam은 RMSprop와 Momentum을 합친 듯한 방법으로, 방향과 학습률 모두를 잡기 위한 방법이다.
- 각 파라미터마다 다른 크기의 업데이트를 적용한다.
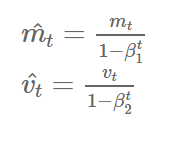
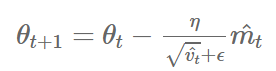
keras.optimizers.Adam(lr=0.001, beta_1=0.9, beta_2=0.999, epsilon=None, decay=0.0, amsgrad=False)
8) AdaMax
- Adam에서의 가중치 업데이트에 대한 규칙은 현재와 과거의 gradient를 개별적으로 보고 있다.
- 이를 표준화 시키면 다음과 같은데, 이는 p가 커질수록 불안정해진다.
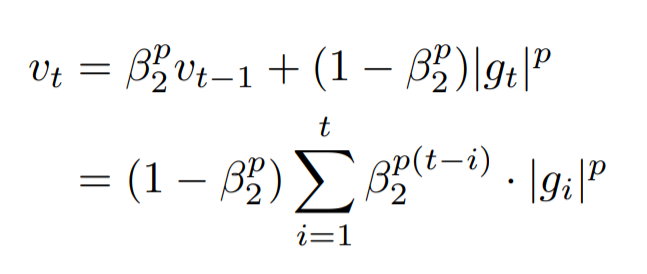
- 하지만 p를 무한대로 보내게 되면, 놀랍게도 안정적인 알고리즘을 보여준다.
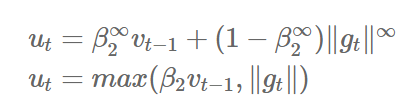
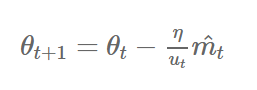
keras.optimizers.Adamax(lr=0.002, beta_1=0.9, beta_2=0.999, epsilon=None, decay=0.0)
9) NAdam(Nesterov-accelerated Adaptive Momentum Adam)
- NAdam은 NAG와 Adam을 섞은 방법이다.
- Adam에서 momentum 대신에 NAG를 사용하여, 미래의 momentum을 사용한 효과를 가진다.
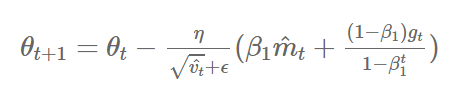
keras.optimizers.Nadam(lr=0.002, beta_1=0.9, beta_2=0.999, epsilon=None, schedule_decay=0.004)
5.2. ANN Implementation
MNIST 데이터 분류하기
Tensorflow
# MNIST
from tensorflow.examples.tutorials.mnist import input_data
mnist = input_data.read_data_sets("data_MNIST", one_hot=True)
import tensorflow as tf
import time
# batch_size : 쪼개서 넣기
# 5000번을 128개 데이터씩 훈련하려면 60만개가 필요하지만, 55000개밖에 없으므로, cost 값이 확 떨어진 경우에 반복적으로 훈련을 실행함
num_steps = 5000
batch_size = 128
nH1 = 256 # 히든 레이어의 유닛을 늘린다는 것은 기준을 세부적으로 더 좁혀주는 것(구체적으로)
nH2 = 256
nH3 = 256
# 조심! 들어오는 사이즈만큼은 히든레이어를 만들어야 한다. 그렇지 않으면 나중에 output layer에서 더 적게 나오게 되어 압축 효과가 생긴다.
X = tf.placeholder("float", [None, 784])
Y = tf.placeholder("float", [None, 10])
# cost function -> 크면 큰대로 살릴 수 있도록 해야 히든레이어를 계속 쌓을 수 있지, 그렇지 않고 1로 제한두면 나머지 값은 사라져버린다.
# 다만 너무 많이 히든레이어를 만들면, 계속해서 시그모이드 함수를 사용하면서 0과 1의 사이로만 출력이 이루어지면서 출력값이 사라지는 문제가 발생한다.
# 따라서 활성화를 시키면 받은만큼 보내는 activation 함수인 'ReLU'를 사용한다.
def mlp_LC(img):
HL1 = tf.nn.relu(tf.add(tf.matmul(img, W['HL1']), b['HL1']))
HL2 = tf.nn.relu(tf.add(tf.matmul(HL1, W['HL2']), b['HL2']))
HL3 = tf.nn.relu(tf.add(tf.matmul(HL2, W['HL3']), b['HL3']))
Out = tf.matmul(HL3, W['Out']) + b['Out']
return Out
# 가중치
W = {
'HL1': tf.Variable(tf.random_normal([784, nH1])),
'HL2': tf.Variable(tf.random_normal([nH1, nH2])),
'HL3': tf.Variable(tf.random_normal([nH2, nH3])),
'Out': tf.Variable(tf.random_normal([nH3, 10]))
}
# 바이어스(유닛)
b = {
'HL1': tf.Variable(tf.random_normal([nH1])),
'HL2': tf.Variable(tf.random_normal([nH2])),
'HL3': tf.Variable(tf.random_normal([nH3])),
'Out': tf.Variable(tf.random_normal([10]))
}
# Model, Cost, Train
model_LC = mlp_LC(X)
model = tf.nn.softmax(model_LC)
cost = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits_v2(logits=model_LC, labels=Y))
train = tf.train.AdamOptimizer(0.01).minimize(cost) # AdamOptimizer -> 이미지를 다룰 때 많이 사용됨
# Accuracy
accuracy = tf.reduce_mean(tf.cast(tf.equal(tf.argmax(model, 1), tf.argmax(Y, 1)), tf.float32))
# Session
with tf.Session() as sess:
sess.run(tf.global_variables_initializer())
# Train
t1 = time.time()
for step in range(1, num_steps+1):
train_images, train_labels = mnist.train.next_batch(batch_size)
sess.run(train, feed_dict={X: train_images, Y: train_labels})
if step % 500 == 0:
print(step)
t2 = time.time()
print("Training Time (seconds): ", t2 - t1)
print("Testing Accuracy: ", sess.run(accuracy, feed_dict={X: mnist.test.images, Y: mnist.test.labels}))
Keras
from keras.utils import np_utils
from keras.datasets import mnist
from keras.models import Sequential
from keras.layers import Dense
# MNIST
(train_images, train_labels), (test_images, test_labels) = mnist.load_data()
print(train_images.shape, train_labels.shape, test_images.shape, test_labels.shape)
# MNIST 훈련 데이터는 총 60,000개로, 28x28픽셀(784)의 이미지로 구성되어 있다.
# 흑백 이미지는 채널이 1개라 reshape를 할 필요가 없지만, 컬러 이미지로 학습시키기 위해선 채널이 3개가 필요하기 때문에 reshape가 필요하다.
# RGB의 값은 0부터 255까지 있는데, 이를 0~1 사이의 값으로 normalize 해주기 위해 255로 나눈다.
train_images = train_images.reshape(train_images.shape[0], 784).astype('float32')/255.0
test_images = test_images.reshape(test_images.shape[0], 784).astype('float32')/255.0
# labels 데이터는 0~9까지의 숫자로 이루어져있으며, 이를 [0, 0, 0, 0, ..., 1]과 같은 원핫 벡터로 변환해줘야 한다.
# 하지만, keras에 있는 labels은 원핫 벡터가 아니라 그냥 1,2,3 이런식으로 들어오기 때문에 레이블링이 필요하다. -> to_categorical
train_labels = np_utils.to_categorical(train_labels) # One-Hot Encoding
test_labels = np_utils.to_categorical(test_labels)
# Model
model = Sequential()
model.add(Dense(256, activation='relu')) # units=256, activation='relu'
model.add(Dense(256, activation='relu'))
model.add(Dense(256, activation='relu'))
model.add(Dense(10, activation='softmax'))
model.compile(loss='categorical_crossentropy', optimizer='sgd', metrics=['accuracy'])
# Training
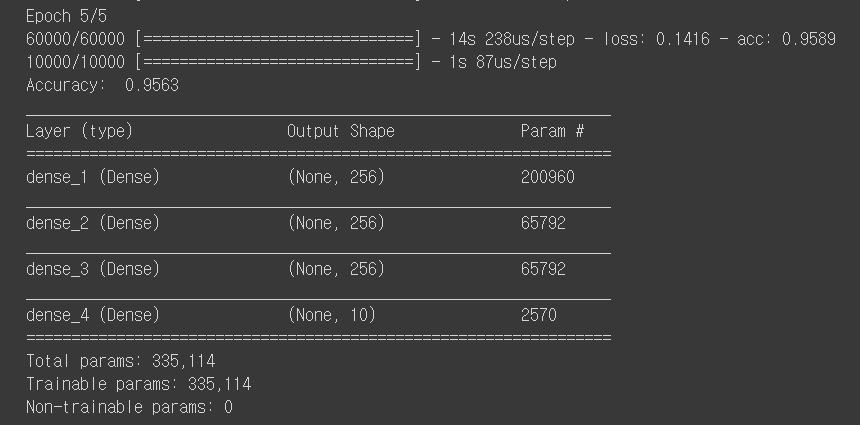
model.fit(train_images, train_labels, epochs=5, batch_size=32, verbose=1)
# Testing
_, accuracy = model.evaluate(test_images, test_labels)
print('Accuracy: ', accuracy)
model.summary() # epoch: 훈련 반복 횟수
dense_1: param -> 784 * 256 + 256(파라미터 업데이트) = 200,960
dense_2: param -> 256 * 256 + 256 = 65,792