7. Recurrent Neural Network(RNN)
7.1. RNN Theory
- RNN
- 히든 노드가 방향을 가진 엣지로 연결돼 순환구조를 이루는(directed cycle) 인공신경망의 한 종류
- 입력과 출력을 시퀀스 단위로 처리하는 모델이다. 입력은 번역하려고 하는 문장으로 단어 시퀀스가 되고, 출력에 해당되는 번역된 문장 또한 단어 시퀀스이다. 이러한 시퀀스들을 처리하기 위해 고안된 모델이 시퀀스 모델이다.
- 텍스트(단어의 시퀀스 또는 문자의 시퀀스), 시계열 데이터에 가장 많이 사용되는 딥러닝 모델이다.
- RNN은 hidden layer의 노드에서 activation 함수를 통해 나온 결과값을 output layer 방향으로 보내면서, 다시 hidden layer의 노드의 다음 계산의 입력으로 사용된다.
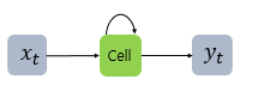
- hidden layer에서 activation 함수를 통해 결과를 내보내는 역할을 하는 노드를 셀(cell)이라고 한다.
- 이 셀은 이전의 값을 기억하려고 하는 일종의 메모리 역할을 수행하므로 메모리 셀 또는 RNN 셀이라고도 표현한다.
- 은닉층의 메모리 셀은 각각의 시점에서 바로 이전 시점에서의 은닉층의 메모리 셀에서 나온 값을 자신의 입력으로 사용하는 재귀적 활동을 하고 있다.
- 현재 시점을 변수 t라고 표현할 때, 현재 시점 t에서의 메모리 셀이 갖고있는 값은 과거의 메모리 셀들의 값에 영향을 받은 것임을 의미한다.
- 메모리 셀이 갖고있는 값을 은닉 상태(hidden state)라고 하며, 출력층 방향으로 또는 다음 시점인 t+1의 자신에게 보내는 값이다.
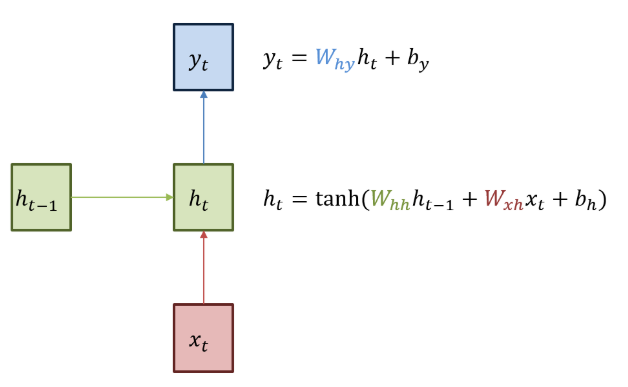
- 녹색 박스는 hidden state를, 빨간 박스는 input data(x), 파란 박스는 output data(y)를 나타낸다.
- 현재 상태의 \(hidden state h_t\)는 이전 시점의 \(hidden state h_(t-1)\)를 받아 갱신한다.
- 현재 상태의 output data인 \(y_t\)는 \(h_t\)를 전달받아 갱신되는 구조이다.
- 히든 상태의 활성화 함수(activation function)는 비선형 함수인 하이퍼볼릭탄젠트(tanh)이다.
- RNN 수식
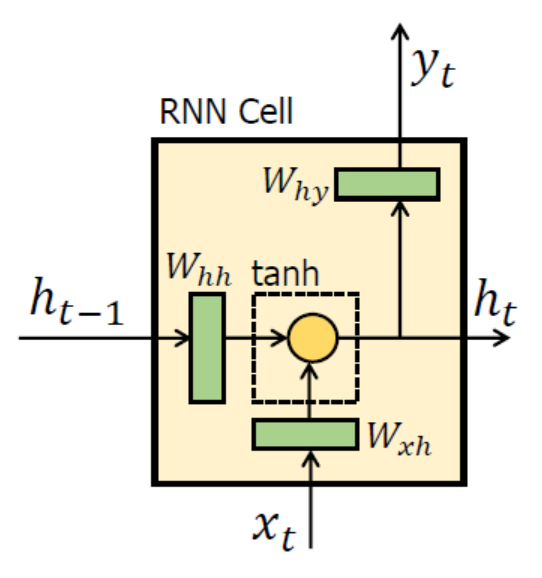
- 현재 시점 t에서의 은닉 상태값을 \(h_t\)라고 하면, 은닉층의 메모리 셀은 \(h_t\)를 계산하기 위해 총 2개의 가중치를 갖는다.
- 하나는 입력층에서 입력값을 위한 가중치 \(W_x\)이고, 다른 하나는 이전 시점 t-1의 은닉 상태값인 \(h_(t-1)\)을 위한 가중치 \(W_h\)이다.
- 이를 식으로 표현하면 다음과 같다.
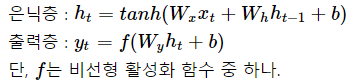
- RNN은 은닉층 연산을 벡터와 행렬 연산으로 이해할 수 있다. 자연어 처리에서 RNN의 입력 \(x_i\)는 대부분의 경우에서 단어 벡터로 간주할 수 있는데, 단어 벡터의 차원을 d라고 하고, 은닉 상태의 크기를 \(D_h\)라고 하였을 때 각 벡터와 행렬의 크기는 다음과 같다.
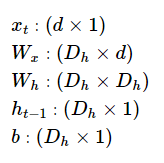
- 배치 크기가 1이고, d와 \(D_h\) 두 값 모두를 4로 가정하면, RNN의 은닉층 연산은 다음과 같다.
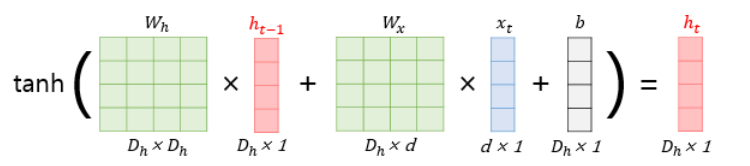
- 각각의 가중치 \(W_x, W_h, W_y\)의 값은 모든 시점에서 값을 동일하게 공유하지만, 은닉층이 2개 이상일 경우 은닉층의 2개의 가중치는 서로 다르다.
- 출력층의 결과값인 \(y_t\)를 계산하기 위한 활성화 함수는 상황에 따라 달라진다. 이진분류의 경우 시그모이드 함수를, 다중 클래스 분류의 경우 소프트맥스 함수를 사용한다.
-
RNN application
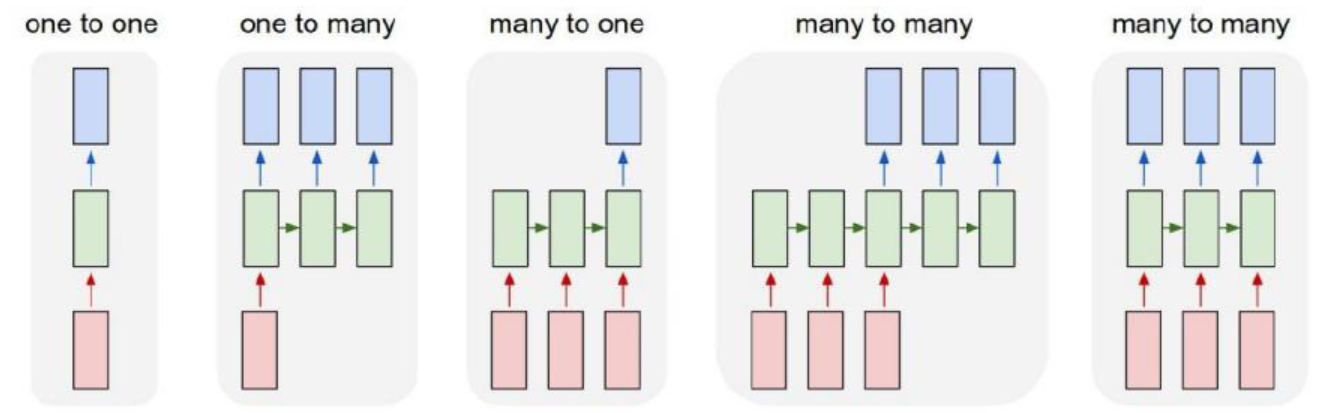
- RNN은 입력과 출력의 길이를 다르게 설계할 수 있으므로 다양한 용도로 사용가능하다.
- one to many: 사진설명 붙이기(사진 -> 단어들)
- many to one: 감성 분석(단어들 -> 감성점수)
- many to many: 번역(단어들 -> 단어들)
7.2. RNN Implement
어떤 글자가 주어졌을 때, 다음 글자를 예측하는 character-level-model 만들기. ex) ‘hihello’
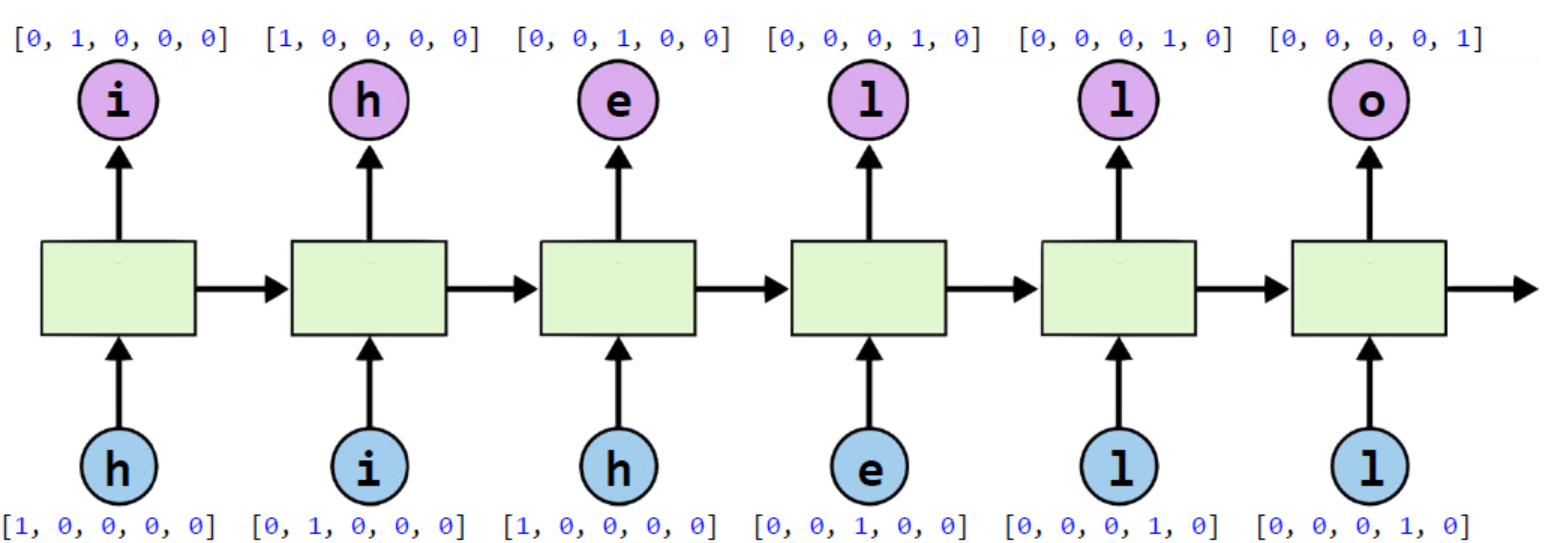
Tensorflow
import tensorflow as tf
import numpy as np
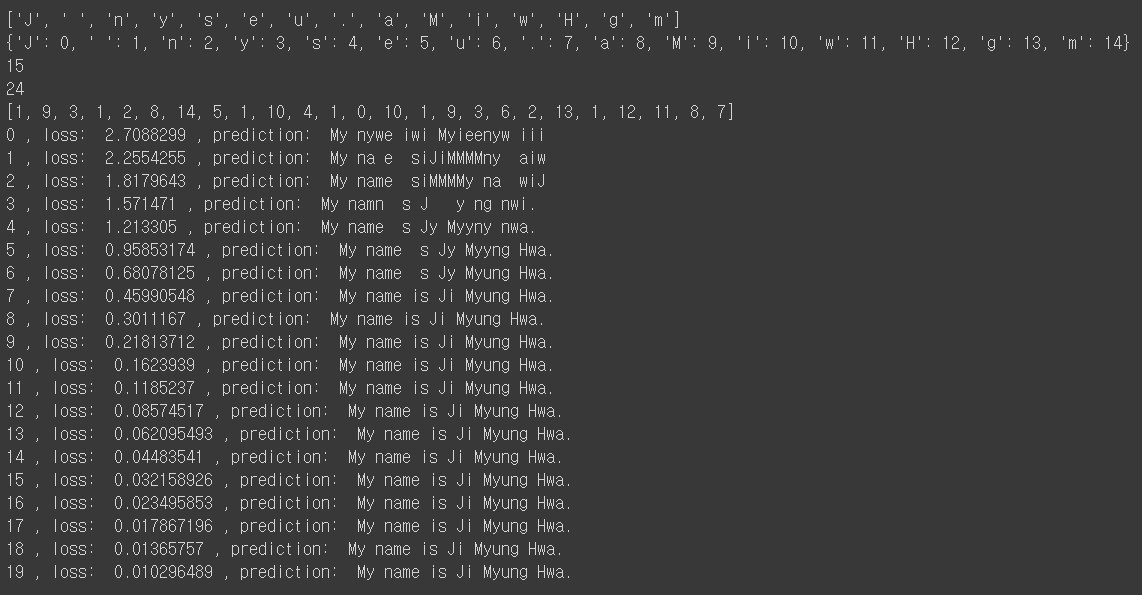
sample = " My name is Ji Myung Hwa."
idx2char = list(set(sample)) # index -> char의 리ㅣ스트
print(idx2char)
char2idx = {c:i for i, c in enumerate(idx2char)} # char -> index의 딕셔너리
print(char2idx)
# hyper parameters
dic_size = len(char2idx) # RNN input size (one hot size)
print(dic_size)
hidden_size = len(char2idx) # RNN output size(num_classes보다 좀 더 큰 것이 좋다)
num_classes = len(char2idx) # final output size (RNN or softmax, etc.) -> one hot encoding 사이즈
batch_size = 1 # one sample data, one batch -> 총 몇 개의 문장을 학습시킬 것인가?
sequence_length = len(sample) - 1 # number of RNN rollings
print(sequence_length)
sample_idx = [char2idx[c] for c in sample] # char to index
print(sample_idx)
x_data = [sample_idx[:-1]] # X data sample (0 ~ n-1) -> 맨 앞에서부터 맨 뒤 한 칸 전까지(p.156 참조)
y_data = [sample_idx[1:]] # Y data sample (1 ~ n) -> 맨 앞의 한 칸 앞에서부터 맨 뒤까지(p.156 참조)
X = tf.placeholder(tf.int32, [None, sequence_length]) # X data -> 인덱스값이므로 정수로 받아야 함
Y = tf.placeholder(tf.int32, [None, sequence_length]) # Y label
x_one_hot = tf.one_hot(X, num_classes)
# cell and RNN
cell = tf.contrib.rnn.BasicRNNCell(num_units=hidden_size)
outputs, _states = tf.nn.dynamic_rnn(cell, x_one_hot, dtype=tf.float32) # RNN의 결과값
# FC Layer
x_for_fc = tf.reshape(outputs, [-1, hidden_size])
outputs = tf.contrib.layers.fully_connected(x_for_fc, num_classes, activation_fn=None)
# reshape out for seqeunce_loss
outputs = tf.reshape(outputs, [batch_size, sequence_length, num_classes]) # 우리가 직접 보는 결과값
sequence_loss = tf.contrib.seq2seq.sequence_loss(logits=outputs, targets=Y, weights=tf.ones([batch_size, sequence_length]))
cost = tf.reduce_mean(sequence_loss)
train = tf.train.AdamOptimizer(0.1).minimize(cost)
prediction = tf.argmax(outputs, axis=2)
with tf.Session() as sess:
sess.run(tf.global_variables_initializer())
for i in range(20):
l, _ = sess.run([cost, train], feed_dict={X: x_data, Y: y_data})
result = sess.run(prediction, feed_dict={X: x_data})
# print char using dic
result_str = [idx2char[c] for c in np.squeeze(result)] # squeeze: 1차원 배열로 축소
print(i, ", loss: ", l, ", prediction: ", "".join(result_str))
Keras
from keras.models import Sequential
from keras.layers import LSTM
from sklearn.model_selection import train_test_split
import numpy as np
import matplotlib.pyplot as plt
x_data = [[[(i+j) / 100] for i in range(5)] for j in range(100)]
y_data = [(i+5) / 100 for i in range(100)]
x_data = np.array(x_data, dtype=float)
y_data = np.array(y_data, dtype=float)
# 훈련 데이터, 테스트 데이터 나누기
x_train, x_test, y_train, y_test = train_test_split(x_data, y_data, test_size=0.2)
model = Sequential()
model.add(LSTM(1, input_dim=1, input_length=5, return_sequences=False))
model.compile(loss='mse', optimizer='adam')
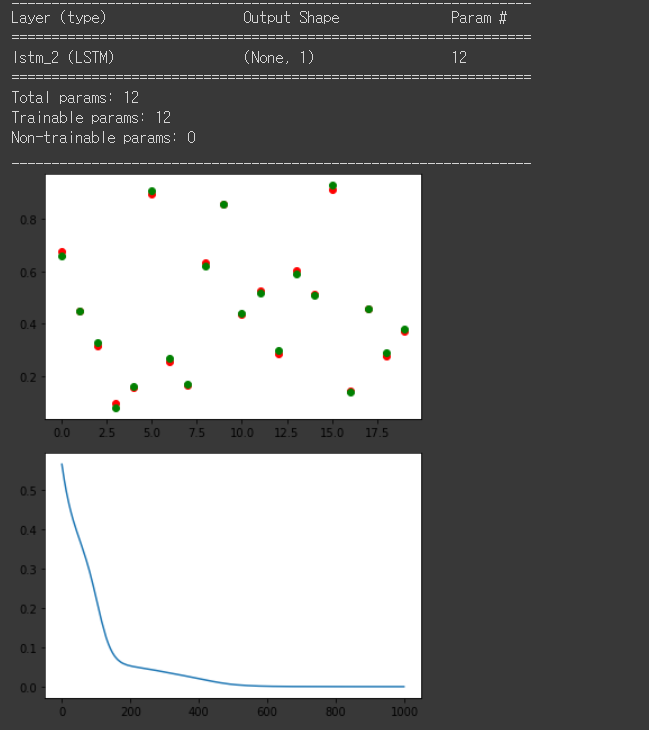
model.summary()
history = model.fit(x_train, y_train, epochs=1000, verbose=0)
y_predict = model.predict(x_test)
plt.scatter(range(20), y_predict, c='r')
plt.scatter(range(20), y_test, c='g')
plt.show()
plt.plot(history.history['loss'])
plt.show()